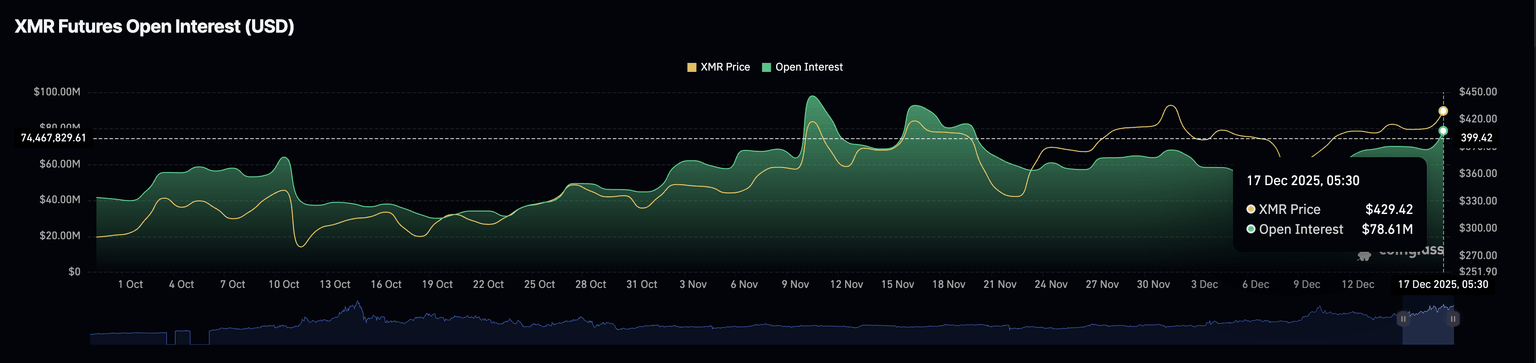
Vitalik: Nueva propuesta de arquitectura de "glue" y coprocesadores para mejorar la eficiencia y la seguridad

El aglutinante debe optimizarse para ser un buen aglutinante, mientras que el coprocesador también debe optimizarse para ser un buen coprocesador.
El "glue" debe optimizarse para ser un buen "glue", y el coprocesador debe optimizarse para ser un buen coprocesador.
Título original: “Glue and coprocessor architectures”
Autor: Vitalik Buterin, fundador de Ethereum
Traducción: Deng Tong, Jinse Finance
Agradecimientos especiales a Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra y varios colaboradores de Flashbots por sus comentarios y sugerencias.
Si analizás con un nivel medio de detalle cualquier cálculo intensivo en recursos que se esté realizando en el mundo moderno, una característica que vas a encontrar una y otra vez es que el cálculo puede dividirse en dos partes:
- Una cantidad relativamente pequeña de “lógica de negocio” compleja pero poco intensiva en cálculo;
- Una gran cantidad de “trabajo costoso” intensivo pero altamente estructurado.
Estas dos formas de cálculo se manejan mejor de maneras diferentes: la primera, cuya arquitectura puede ser menos eficiente pero requiere una gran generalidad; la segunda, cuya arquitectura puede ser menos general pero necesita ser extremadamente eficiente.
¿Cuáles son ejemplos prácticos de este enfoque diferente?
Primero, veamos el entorno que mejor conozco: la Ethereum Virtual Machine (EVM). Este es el rastreo de depuración de geth de una transacción de Ethereum que hice recientemente: actualizar el hash de IPFS de mi blog en ENS. La transacción consumió un total de 46,924 gas, que se puede clasificar de la siguiente manera:
- Costo básico: 21,000
- Datos de llamada: 1,556
- Ejecución EVM: 24,368
- Opcode SLOAD: 6,400
- Opcode SSTORE: 10,100
- Opcode LOG: 2,149
- Otros: 6,719

Rastreo EVM de la actualización del hash ENS. La penúltima columna es el consumo de gas.
La moraleja de esta historia es: la mayor parte de la ejecución (alrededor del 73% si solo miramos la EVM, o alrededor del 85% si incluimos la parte del costo básico que cubre el cálculo) se concentra en un puñado de operaciones costosas y estructuradas: lecturas y escrituras de almacenamiento, logs y criptografía (el costo básico incluye 3,000 para pagar la verificación de firmas, y la EVM incluye 272 para pagar hashes). El resto de la ejecución es “lógica de negocio”: cambiar los bits de calldata para extraer el ID del registro que intento establecer y el hash al que lo estoy configurando, etc. En una transferencia de tokens, esto incluiría sumar y restar saldos; en aplicaciones más avanzadas, podría incluir bucles, etc.
En la EVM, estas dos formas de ejecución se manejan de manera diferente. La lógica de negocio de alto nivel se escribe en lenguajes de alto nivel, normalmente Solidity, que se compila a EVM. El trabajo costoso aún es activado por opcodes de la EVM (como SLOAD), pero más del 99% del cálculo real se realiza en módulos especializados escritos directamente en el código del cliente (o incluso en librerías).
Para reforzar la comprensión de este patrón, exploremos otro contexto: código de IA escrito en Python usando torch.
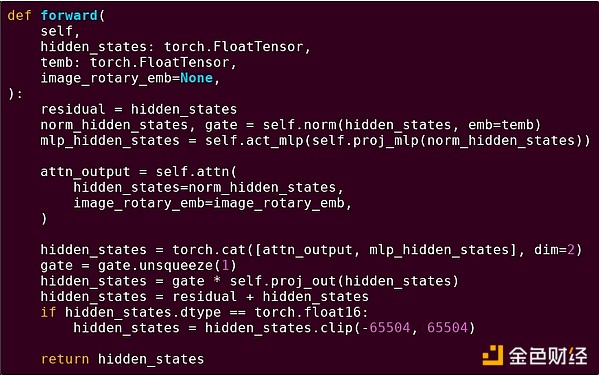
Paso hacia adelante de un bloque de un modelo transformer
¿Qué vemos aquí? Vemos una cantidad relativamente pequeña de “lógica de negocio” escrita en Python, que describe la estructura de las operaciones que se están ejecutando. En la práctica, también habrá otro tipo de lógica de negocio que decide detalles como cómo obtener la entrada y qué hacer con la salida. Pero si profundizamos en cada operación individual (self.norm, torch.cat, +, *, los pasos internos de self.attn, etc.), vemos cálculos vectorizados: la misma operación calculada en paralelo sobre muchos valores. Al igual que en el primer ejemplo, una pequeña parte del cálculo es para la lógica de negocio, y la mayor parte es para ejecutar grandes operaciones estructuradas de matrices y vectores — de hecho, la mayoría son multiplicaciones de matrices.
Al igual que en el ejemplo de la EVM, estos dos tipos de trabajo se manejan de dos maneras diferentes. El código de lógica de negocio de alto nivel está escrito en Python, un lenguaje altamente general y flexible, pero también muy lento; simplemente aceptamos la ineficiencia porque solo involucra una pequeña parte del costo total de cálculo. Mientras tanto, las operaciones intensivas están escritas en código altamente optimizado, normalmente código CUDA que se ejecuta en GPU. Incluso cada vez más vemos inferencia de LLMs en ASICs.
La criptografía programable moderna, como SNARK, sigue nuevamente un patrón similar en dos niveles. Primero, el probador puede estar escrito en un lenguaje de alto nivel, donde el trabajo pesado se realiza mediante operaciones vectorizadas, igual que en el ejemplo de IA anterior. Mi código circular de STARK aquí lo demuestra. Segundo, el propio programa que se ejecuta dentro de la criptografía puede escribirse de una manera que se divida entre lógica de negocio general y trabajo costoso altamente estructurado.
Para entender cómo funciona, podemos mirar una de las tendencias recientes en pruebas STARK. Para ser generales y fáciles de usar, los equipos están construyendo cada vez más probadores STARK para máquinas virtuales mínimas ampliamente adoptadas, como RISC-V. Cualquier programa que necesite ser probado puede compilarse a RISC-V, y luego el probador puede probar la ejecución de ese código en RISC-V.
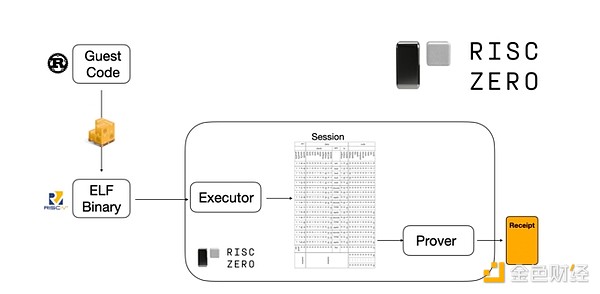
Gráfico de la documentación de RiscZero
Esto es muy conveniente: significa que solo necesitamos escribir la lógica de prueba una vez, y a partir de ahí, cualquier programa que necesite ser probado puede escribirse en cualquier lenguaje de programación “tradicional” (por ejemplo, RiskZero soporta Rust). Pero hay un problema: este enfoque genera una gran sobrecarga. La criptografía programable ya es muy costosa; añadir la sobrecarga de ejecutar el código en un intérprete RISC-V es demasiado. Por eso, los desarrolladores idearon un truco: identificar operaciones costosas específicas que constituyen la mayor parte del cálculo (normalmente hashes y firmas), y luego crear módulos especializados para probar estas operaciones de manera muy eficiente. Así, simplemente combinando el sistema de pruebas RISC-V, que es ineficiente pero general, con sistemas de pruebas eficientes pero especializados, se obtiene lo mejor de ambos mundos.
La criptografía programable más allá de ZK-SNARK, como el cálculo multipartito (MPC) y la encriptación homomórfica completa (FHE), también puede optimizarse usando métodos similares.
En general, ¿cómo es este fenómeno?
El cálculo moderno sigue cada vez más lo que llamo la arquitectura de glue y coprocesador: tenés un componente central de “glue”, que es altamente general pero ineficiente, encargado de transferir datos entre uno o más componentes coprocesadores, que son poco generales pero muy eficientes.
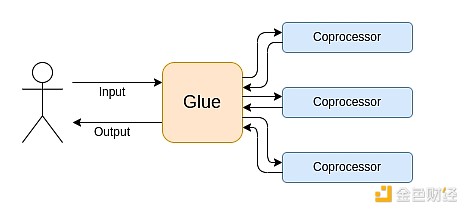
Esto es una simplificación: en la práctica, la curva de trade-off entre eficiencia y generalidad casi siempre tiene más de dos niveles. Las GPU y otros chips comúnmente llamados “coprocesadores” en la industria no son tan generales como las CPU, pero son más generales que los ASICs. El trade-off de especialización es complejo y depende de predicciones e intuiciones sobre qué partes del algoritmo seguirán siendo iguales en cinco años y cuáles cambiarán en seis meses. En la arquitectura de pruebas ZK, a menudo vemos una especialización multinivel similar. Pero para un modelo mental amplio, considerar dos niveles es suficiente. Hay situaciones similares en muchos campos del cálculo:
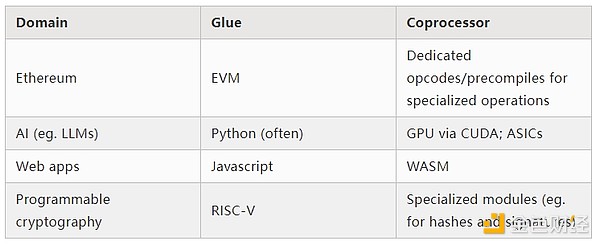
Por los ejemplos anteriores, claramente el cálculo puede dividirse de esta manera, lo que parece una ley natural. De hecho, se pueden encontrar ejemplos de especialización en el cálculo desde hace décadas. Sin embargo, creo que esta separación está aumentando. Y creo que hay razones para ello:
Recién recientemente hemos alcanzado el límite de aumento de la velocidad de reloj de las CPU, por lo que solo se pueden obtener más beneficios mediante la paralelización. Pero la paralelización es difícil de razonar, por lo que para los desarrolladores suele ser más práctico seguir razonando secuencialmente y dejar que la paralelización ocurra en el backend, envuelta en módulos especializados para operaciones específicas.
La velocidad de cálculo solo recientemente se ha vuelto tan alta que el costo de cálculo de la lógica de negocio se ha vuelto realmente despreciable. En este mundo, también tiene sentido optimizar la VM que ejecuta la lógica de negocio para objetivos distintos a la eficiencia computacional: facilidad de desarrollo, familiaridad, seguridad y otros objetivos similares. Al mismo tiempo, los módulos “coprocesadores” especializados pueden seguir siendo diseñados para la eficiencia y obtener su seguridad y facilidad de desarrollo de su “interfaz” relativamente simple con el glue.
Cuáles son las operaciones costosas más importantes se está volviendo cada vez más claro. Esto es más evidente en la criptografía, donde es más probable que se usen ciertos tipos de operaciones costosas: operaciones modulares, combinaciones lineales de curvas elípticas (también conocidas como multiplicación multiescalar), transformadas rápidas de Fourier, etc. En IA, esto también se está volviendo cada vez más claro: durante más de veinte años, la mayoría del cálculo ha sido “principalmente multiplicación de matrices” (aunque con diferentes niveles de precisión). Otras áreas muestran tendencias similares. En comparación con hace 20 años, hay muchas menos incógnitas desconocidas en el cálculo (intensivo en recursos).
¿Qué significa esto?
Un punto clave es que el glue debe optimizarse para ser un buen glue, y el coprocesador debe optimizarse para ser un buen coprocesador. Podemos explorar el significado de esto en varias áreas clave.
EVM
Las máquinas virtuales blockchain (como la EVM) no necesitan ser eficientes, solo familiares. Simplemente agregando los coprocesadores correctos (también llamados “precompilados”), el cálculo en una VM ineficiente puede ser tan eficiente como en una VM nativa eficiente. Por ejemplo, la sobrecarga de los registros de 256 bits de la EVM es relativamente pequeña, mientras que los beneficios de la familiaridad de la EVM y el ecosistema de desarrolladores existente son enormes y duraderos. Los equipos que optimizan la EVM incluso han descubierto que la falta de paralelización generalmente no es el principal obstáculo para la escalabilidad.
La mejor manera de mejorar la EVM probablemente sea (i) agregar mejores precompilados u opcodes especializados, por ejemplo, alguna combinación de EVM-MAX y SIMD podría ser razonable, y (ii) mejorar la disposición del almacenamiento, por ejemplo, los cambios de Verkle tree como efecto secundario reducen enormemente el costo de acceder a slots de almacenamiento adyacentes.
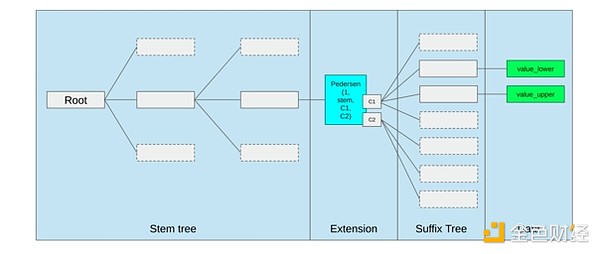
Optimización de almacenamiento en la propuesta de Verkle tree de Ethereum, agrupando claves de almacenamiento adyacentes y ajustando el costo de gas para reflejarlo. Optimizaciones como esta, junto con mejores precompilados, pueden ser más importantes que ajustar la EVM en sí.
Cálculo seguro y hardware abierto
Un gran desafío para mejorar la seguridad del cálculo moderno a nivel de hardware es su naturaleza demasiado compleja y propietaria: los chips se diseñan para ser eficientes, lo que requiere optimizaciones propietarias. Es fácil ocultar puertas traseras, y las vulnerabilidades de canal lateral se descubren constantemente.
Se sigue trabajando desde varios ángulos para impulsar alternativas más abiertas y seguras. Cada vez más cálculos se realizan en entornos de ejecución confiables, incluso en el teléfono del usuario, lo que ya ha mejorado la seguridad del usuario. El impulso por hardware de consumo más open source continúa, con algunos logros recientes como laptops RISC-V que ejecutan Ubuntu.
Laptop RISC-V ejecutando Debian
Sin embargo, la eficiencia sigue siendo un problema. El autor del artículo enlazado arriba escribe:
Diseños de chips open source más nuevos como RISC-V no pueden igualar la tecnología de procesadores que ya existe y ha sido mejorada durante décadas. Todo progreso tiene un punto de partida.
Ideas más paranoicas, como este diseño de una computadora RISC-V construida en FPGA, enfrentan una sobrecarga aún mayor. Pero, ¿qué pasaría si la arquitectura de glue y coprocesador significara que esta sobrecarga en realidad no importa? ¿Y si aceptamos que los chips abiertos y seguros serán más lentos que los propietarios, y si es necesario incluso renunciamos a optimizaciones comunes como la ejecución especulativa y la predicción de saltos, pero intentamos compensar esto agregando módulos ASIC (si es necesario, propietarios) para los tipos de cálculo más intensivos? El cálculo sensible puede realizarse en el “chip principal”, que se optimizará para seguridad, diseño open source y resistencia a canales laterales. El cálculo más intensivo (por ejemplo, pruebas ZK, IA) se realizará en módulos ASIC, que conocerán menos información sobre el cálculo que se está ejecutando (posiblemente, mediante enmascaramiento criptográfico, en algunos casos incluso cero información).
Criptografía
Otro punto clave es que todo esto es muy optimista para la criptografía, especialmente para que la criptografía programable se vuelva mainstream. Ya hemos visto implementaciones súper optimizadas de cálculos altamente estructurados específicos en SNARK, MPC y otros entornos: la sobrecarga de ciertos hashes es solo unas pocas centenas de veces más costosa que ejecutar el cálculo directamente, y la sobrecarga para IA (principalmente multiplicación de matrices) es muy baja. Mejoras adicionales como GKR pueden reducir aún más este nivel. La ejecución de VM completamente general, especialmente cuando se ejecuta en un intérprete RISC-V, puede seguir generando una sobrecarga de alrededor de diez mil veces, pero por las razones descritas en este artículo, esto no importa: siempre que las partes más intensivas del cálculo se manejen por separado con técnicas especializadas y eficientes, la sobrecarga total es controlable.
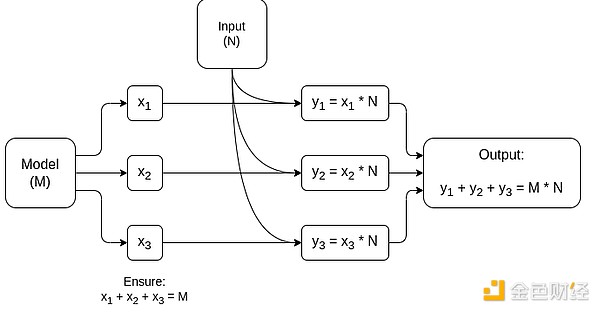
Diagrama simplificado de MPC especializado en multiplicación de matrices, el mayor componente en la inferencia de modelos de IA. Ver este artículo para más detalles, incluyendo cómo mantener la privacidad del modelo y las entradas.
Una excepción a la idea de que “la capa glue solo necesita ser familiar, no eficiente” es la latencia, y en menor medida el ancho de banda de datos. Si el cálculo implica operaciones pesadas repetidas decenas de veces sobre los mismos datos (como en criptografía e IA), cualquier latencia causada por una capa glue ineficiente puede convertirse en el principal cuello de botella del tiempo de ejecución. Por lo tanto, la capa glue también tiene requisitos de eficiencia, aunque estos son más específicos.
Conclusión
En general, creo que las tendencias anteriores son desarrollos muy positivos desde múltiples ángulos. Primero, es una forma razonable de maximizar la eficiencia del cálculo manteniendo la facilidad de desarrollo, permitiendo obtener más de ambos para beneficio de todos. En particular, al especializar en el cliente para mejorar la eficiencia, aumenta nuestra capacidad de ejecutar cálculos sensibles y de alto rendimiento (como pruebas ZK, inferencia de LLM) localmente en el hardware del usuario. Segundo, crea una gran ventana de oportunidad para asegurar que la búsqueda de eficiencia no comprometa otros valores, especialmente seguridad, apertura y simplicidad: seguridad y apertura frente a canales laterales en hardware de computadoras, reducción de la complejidad de circuitos en ZK-SNARK y reducción de la complejidad en máquinas virtuales. Históricamente, la búsqueda de eficiencia relegó estos otros factores a un segundo plano. Con la arquitectura de glue y coprocesador, ya no es necesario. Una parte de la máquina se optimiza para eficiencia, la otra para generalidad y otros valores, y ambas trabajan juntas.
Esta tendencia también es muy favorable para la criptografía, porque la criptografía en sí misma es un ejemplo principal de “cálculo estructurado costoso”, y esta tendencia acelera ese desarrollo. Esto agrega otra oportunidad para mejorar la seguridad. En el mundo blockchain, también es posible mejorar la seguridad: podemos preocuparnos menos por la optimización de la máquina virtual y centrarnos más en optimizar precompilados y otras funciones que coexisten con la máquina virtual.
En tercer lugar, esta tendencia brinda oportunidades para participantes más pequeños y nuevos. Si el cálculo se vuelve menos monolítico y más modular, la barrera de entrada se reduce considerablemente. Incluso con un ASIC para un solo tipo de cálculo, es posible marcar la diferencia. Esto también es cierto en el campo de pruebas ZK y en la optimización de la EVM. Escribir código con eficiencia casi de vanguardia se vuelve más fácil y accesible. Auditar y verificar formalmente dicho código también se vuelve más fácil y accesible. Finalmente, dado que estos campos de cálculo tan diferentes están convergiendo hacia algunos patrones comunes, hay más espacio para la colaboración y el aprendizaje entre ellos.
Descargo de responsabilidad: El contenido de este artículo refleja únicamente la opinión del autor y no representa en modo alguno a la plataforma. Este artículo no se pretende servir de referencia para tomar decisiones de inversión.
También te puede gustar
Google profundiza su apuesta por el crédito al consumidor en India con una tarjeta vinculada a UPI