
衝上熱搜!美團大模型,靠「快」火了

國內外開發者:親測,美團新開源的模型速度超快!
當 AI 真的變得像水和電一樣普及之後,模型強不強已經不是大家唯一關心的問題了。
從年初的 Claude 3.7 Sonnet、Gemini 2.5 Flash 到最近的 GPT-5、DeepSeek V3.1,走在前面的模型廠商無一不在思考:在保證準確性的前提下,如何讓 AI 既能以最少的算力去解決每一個問題,又能在最短的時間內給出回應?換句話說,就是如何做到既不浪費 token,也不浪費時間。
對於在模型上構建應用的企業和開發者來說,這種從「單純構建最強模型到構建更實用、更快速模型」的轉變是個好消息。而且更加令人欣慰的是,與之相關的開源模型也逐漸多了起來。
前幾天,我們在 HuggingFace 上又發現了一個新模型 ——LongCat-Flash-Chat。

這個模型來自美團的 LongCat-Flash 系列,官網可以直接使用。
它天生知道「not all tokens are equal」,因此會根據重要性為重要 token 分配動態計算預算。這讓它在僅激活少量參數的前提下,性能就能並肩當下領先的開源模型。

LongCat-Flash 開源後登上熱搜。
同時,這個模型的速度也給大家留下了深刻印象 —— 在 H800 顯卡上推理速度超過每秒 100 個 token。國內外開發者的實測都證實了這一點 —— 有人跑出了 95 tokens/s 的速度,有人在最短時間內得到了和 Claude 相媲美的答案。
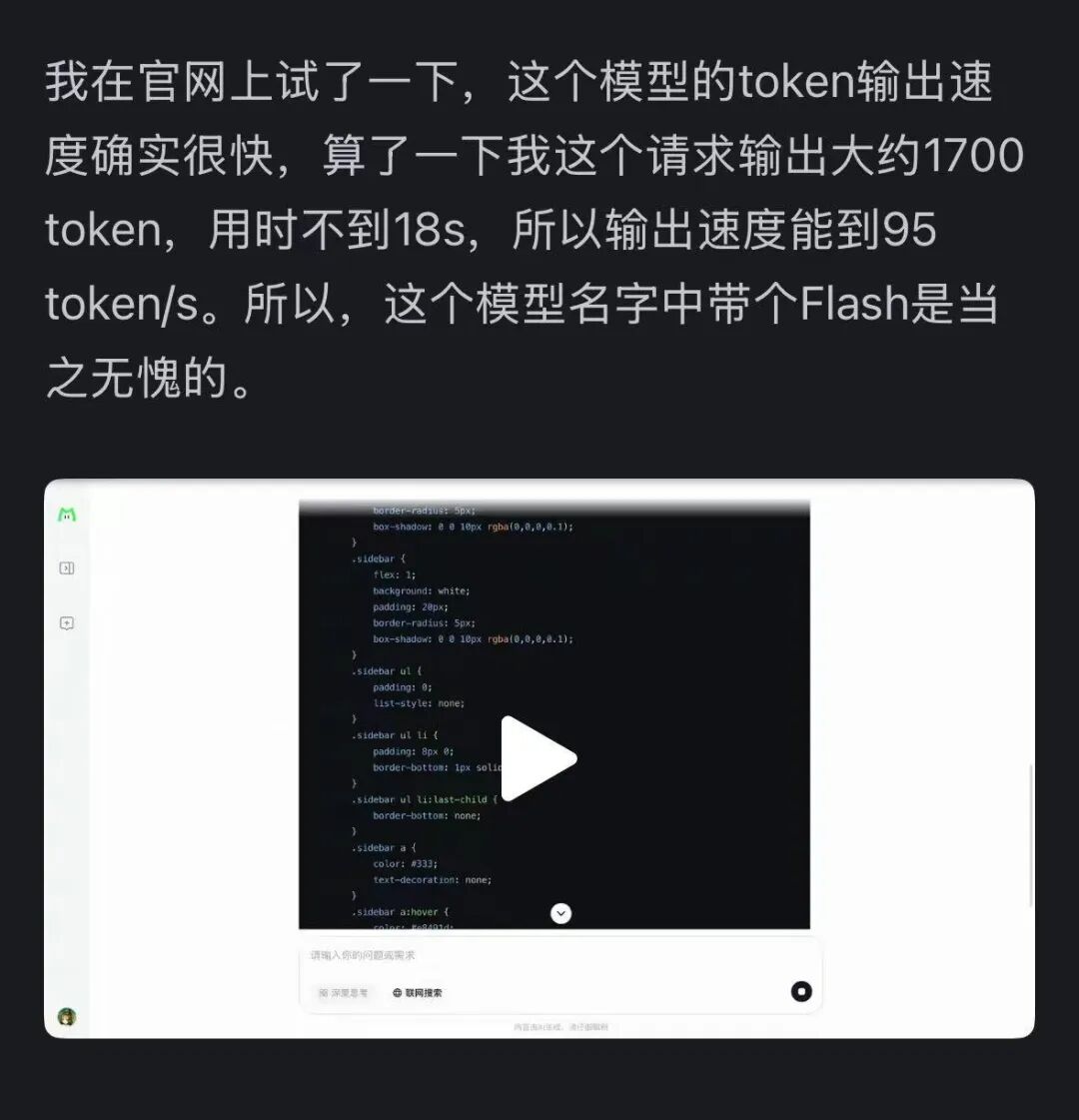
圖源:知乎網友 @小小將。
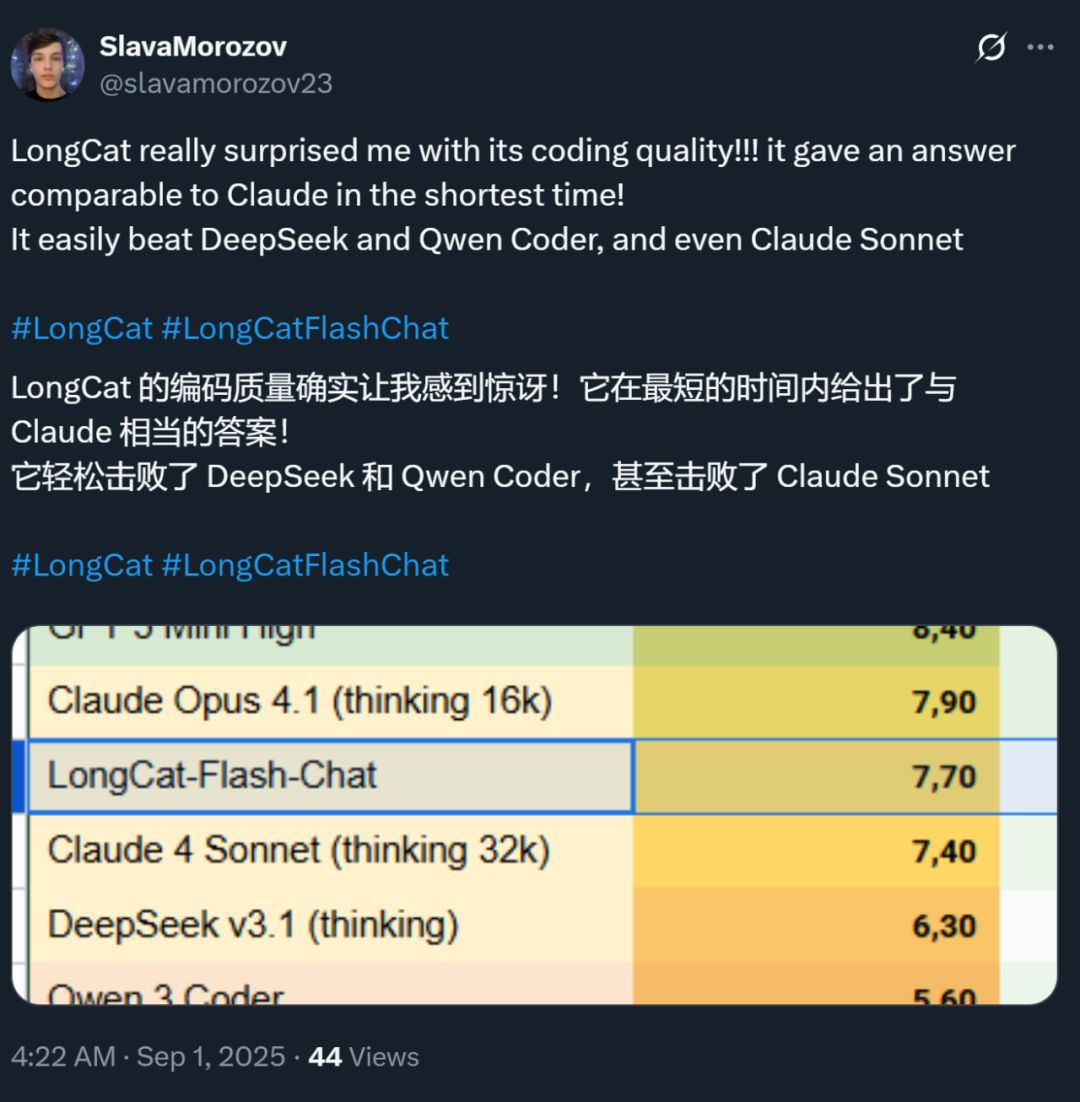
圖源:X 網友 @SlavaMorozov。
在開源模型的同時,美團也放出了 LongCat-Flash 的技術報告,我們可以在其中看到不少技術細節。

技術報告:LongCat-Flash Technical Report
在這篇文章中,我們將詳細介紹。
大模型怎麼省算力?
看看 LongCat-Flash 的架構創新和訓練方法
LongCat-Flash 是一個混合專家模型,總參數量為5600 億,可以根據上下文需求激活 186 億至 313 億(平均 270 億)個參數。
用來訓練該模型的數據量超過 20 萬億 token,但訓練時間卻只用了不到 30 天。而且在這段時間裡,系統達到了98.48% 的時間可用率,幾乎不需要人工干預來處理故障 —— 這意味著整個訓練過程基本是「無人干預」自動完成的。
更讓人印象深刻的是,這樣訓練出來的模型在實際部署時表現同樣出色。
如下圖所示,作為一款非思考型模型,LongCat-Flash 達到了與 SOTA 非思考型模型相當的性能,包括 DeepSeek-V3.1 和 Kimi-K2,同時參數更少且推理速度更快。這讓它在通用、編程、智能體工具使用等方向都頗具競爭力和實用性。
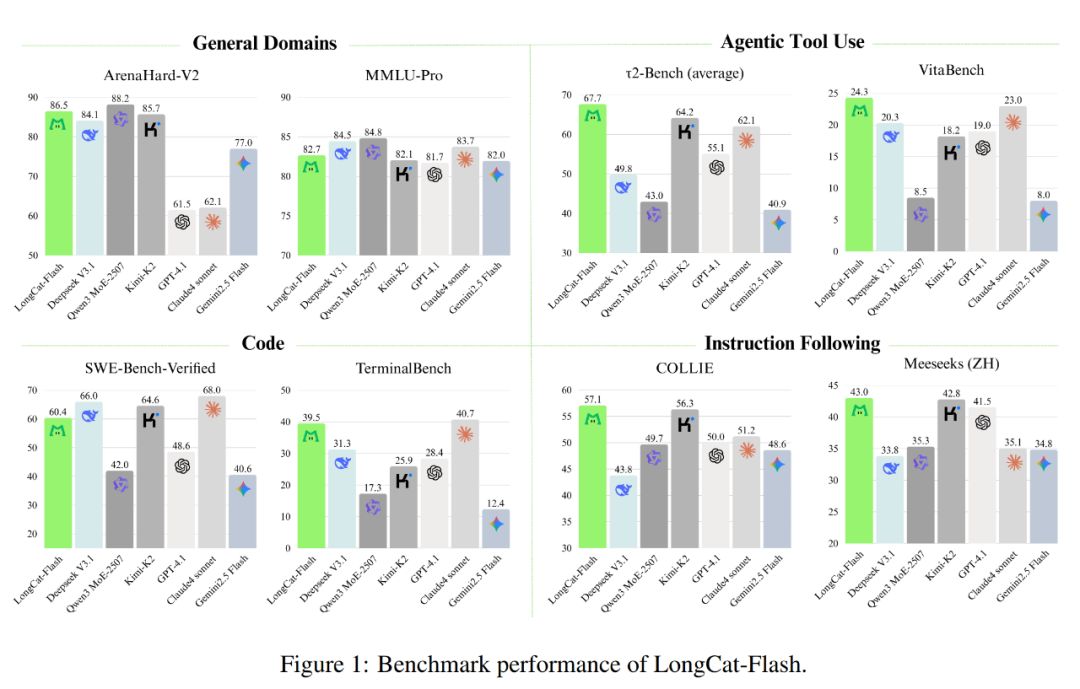
此外,它的成本也很亮眼,僅為每百萬輸出 token 0.7 美元。這個價格相比市面上同等規模的模型來說,可以算是非常划算了。
從技術上來說,LongCat-Flash 主要瞄準語言模型的兩個目標:計算效率與智能體能力,並融合了架構創新與多階段訓練方法,從而實現可擴展且智能的模型體系。
在模型架構方面,LongCat-Flash 採用了一種新穎的 MoE 架構(圖 2),其亮點包含兩方面:
零計算專家(Zero-computation Experts);
快捷連接 MoE(Shortcut-connected MoE,ScMoE)。
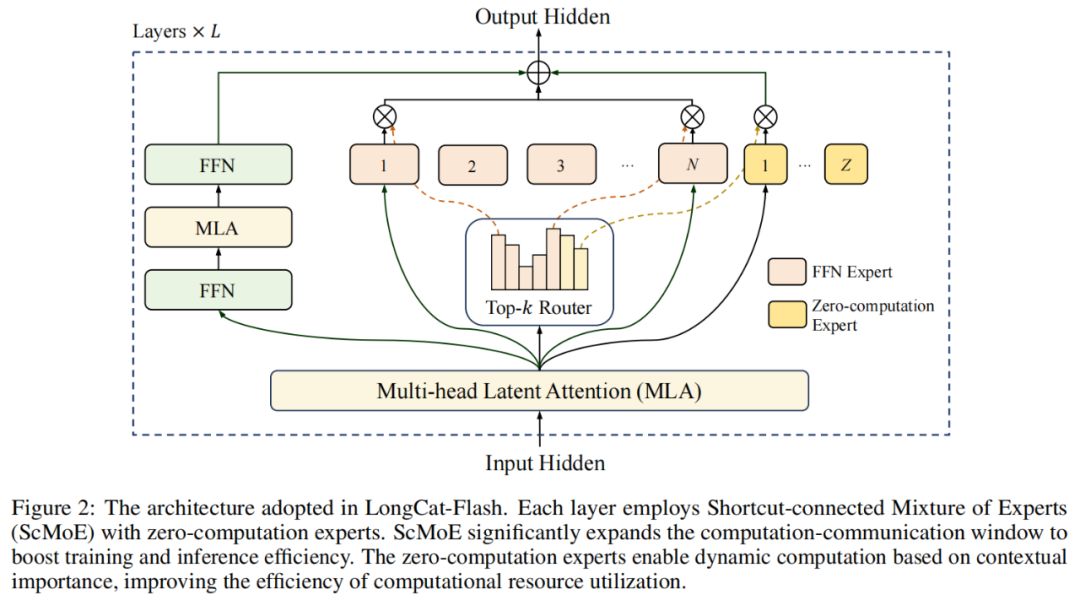
零計算專家
零計算專家的核心思想是並非所有 token 都是「平等」的。
我們可以這樣理解,在一個句子中,有些詞是非常容易預測的,如「的」「是」,幾乎不需要計算,而有些詞如「人名」則需要大量計算才能準確預測。
在以往的研究中,大家基本採用這種方式:即無論這個 token 是簡單還是複雜,它都會激活固定數量( K )的專家,這造成了巨大的計算浪費。對於簡單 token 來說,完全沒必要調用那麼多專家,而對於複雜 token,則可能又缺乏足夠的計算分配。
受此啟發,LongCat-Flash 提出了一種動態計算資源分配機制:通過零計算專家,為每個 token 動態激活不同數量的 FFN(Feed-Forward Network)專家,從而根據上下文的重要性更合理地分配計算量。
具體而言,LongCat-Flash 在其專家池中,除了原有的 N 個標準 FFN 專家外,還擴展了 Z 個零計算專家。零計算專家僅將輸入原樣返回作為輸出,因此不會引入額外的計算開銷。
LongCat-Flash 中的 MoE 模組可以形式化為:
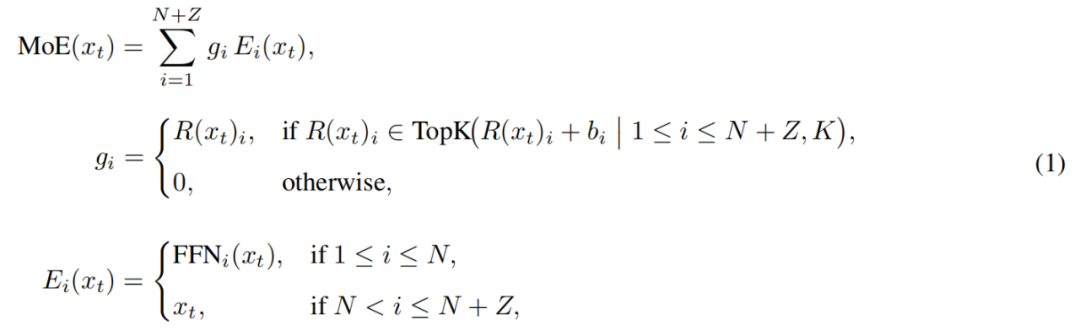
其中,x_t 為輸入序列中的第 t 個 token,R 表示 softmax 路由器,b_i 表示第 i 個專家對應的偏置項,K 表示每個 token 所選中的專家數量。路由器會將每個 token 分配給 K 個專家,其中被激活的 FFN 專家數量會根據該 token 的上下文重要性而變化。通過這種自適應的分配機制,模型能夠學習到對上下文更重要的 token 動態分配更多的計算資源,從而在相同的計算量條件下實現更優的性能,如圖 3a 所示。
另外,模型在處理輸入時,需要學會根據不同 token 的重要性,來決定到底要不要花更多計算資源。如果不去控制零計算專家被選中的頻率,模型可能會偏向於選擇有計算的專家,忽視零計算專家的作用。從而造成計算資源效率低下。
為了解決這一問題,美團改進了 aux-loss-free 策略中的專家偏置機制:引入專家特定的偏置項,該偏置能夠根據最近的專家使用情況動態調整路由分數,同時又與語言模型的訓練目標保持解耦。
更新規則採用了控制理論中的 PID 控制器實時微調專家偏置。得益於此,模型在處理每個 token 時,僅需激活 186 億至 313 億(平均激活量穩定在約 270 億)的參數量,從而實現資源優化配置。
快捷連接 MoE
LongCat-Flash 另一個亮點是快捷連接 MoE 機制。
一般而言,大規模 MoE 模型的效率在很大程度上受到通信開銷的限制。在傳統的執行範式中,專家並行會引入一種順序化的工作流程,即必須先通過一次全局通信操作將 token 路由到其指定的專家,隨後計算才能開始。
這種先通信、再計算的順序會帶來額外的等待時間,尤其在大規模分布式訓練中,通信延遲會顯著增加,成為性能瓶頸。
此前有研究者採用共享專家架構,試圖通過將通信與單個專家的計算重疊來緩解問題,但其效率受到單個專家計算窗口過小的限制。
美團通過引入 ScMoE 架構克服了這一限制,ScMoE 在層間引入了一條跨層快捷連接,這一關鍵創新使得:前一層稠密 FFN 的計算可以與當前 MoE 層的分發 / 聚合通信操作並行執行,相比共享專家架構,形成了一個更大規模的通信 - 計算重疊窗口。
該架構設計在多項實驗中得到了驗證。
首先,ScMoE 設計並不會降低模型質量。如圖 4 所示,ScMoE 架構與未使用 ScMoE 的基線在訓練損失曲線上的表現幾乎完全一致,這證明了這種重新排序的執行方式並不會損害模型性能。這一結論在多種配置下均得到一致性驗證。
更重要的是,這些結果表明:ScMoE 的穩定性與性能優勢,與注意力機制的具體選擇是正交的(即無論使用哪種注意力機制,都能保持穩定與收益)。
其次,ScMoE 架構為訓練和推理提供了大量系統級效率提升。具體表現在:
在大規模訓練方面:擴展的重疊窗口使前序塊的計算能夠與 MoE 層中的分發和聚合通信階段完全並行,這是通過沿 token 維度將操作分割為細粒度塊實現的。
在高效推理方面:ScMoE 支持單批次重疊 pipeline,相較 DeepSeek-V3 等領先模型,將理論每秒輸出 token 時間(TPOT)降低近 50%。更重要的是,它允許不同通信模式的並發執行:稠密 FFN 上節點內的張量並行通信(通過 NVLink)可與節點間的專家並行通信(通過 RDMA)完全重疊,從而最大化總體網路利用率。
總之,ScMoE 在不犧牲模型質量的情況下提供了大量的性能提升。
模型擴展策略與多階段訓練
美團還提出了一套高效的模型擴展策略,能夠顯著改善模型在規模增大時的性能表現。
首先是超參數遷移,在訓練超大規模模型時,直接嘗試各種超參數配置非常昂貴且不穩定。於是美團先在較小的模型上進行實驗,找到效果最好的超參數組合。然後,再把這些參數遷移到大模型上使用。從而節省了成本並保證了效果。遷移規則如表 1 所示:
其次是模型增長(Model Growth)初始化,美團先從一個在數百億 token 上預訓練過的半規模模型出發,訓練好之後保留檢查點。在此基礎上把模型擴展到完整規模,並繼續訓練。
基於這種方式,模型表現出一條典型的損失曲線:損失先短暫上升,隨後快速收斂,並最終顯著優於隨機初始化的基線。圖 5b 展示 6B 激活參數實驗中的一個代表性結果,體現了模型增長初始化的優勢。
第三點是多層次的穩定性套件,美團從路由器穩定性、激活穩定性和優化器穩定性三個方面增強了 LongCat-Flash 的訓練穩定性。
第四點是確定性計算,這種方法能夠保證實驗結果的完全可複現,並在訓練過程中實現對靜默數據損壞(Silent Data Corruption, SDC)的檢測。
通過這些措施,LongCat-Flash 的訓練過程始終保持高度穩定,且不會出現不可恢復的損失驟增(loss spike)。
在保持訓練穩定的基礎上,美團還精心設計了訓練 pipeline,使 LongCat-Flash 具備了高級智能體行為,該流程涵蓋大規模預訓練、面向推理與代碼能力的中期訓練,以及聚焦對話與工具使用的後訓練。
初始階段,構建一個更適合於智能體後訓練的基礎模型,為此美團設計了一個兩階段的預訓練數據融合策略來集中推理密集型領域的數據。
訓練中期,美團進一步增強模型的推理能力與代碼能力;同時將上下文長度擴展至 128k,以滿足智能體後訓練的需求。
最後,美團又進行了多階段後訓練。鑑於智能體領域高質量、高難度訓練數據的稀缺,美團設計了一個多智能體合成框架:該框架從三個維度定義任務難度,即信息處理、工具集複雜性和用戶交互,使用專門的控制器來生成需要迭代推理和環境交互的複雜任務。
這種設計使其在執行需要調用工具、與環境交互的複雜任務時表現出色。
跑起來又快又便宜
LongCat-Flash 是怎麼做到的?
前面提到,LongCat-Flash 可以在 H800 顯卡上以超過每秒 100 個 token 的速度進行推理,成本僅為每百萬輸出 token 0.7 美元,可以說跑起來又快又便宜。
這是怎麼做到的呢?首先,他們有一個與模型架構協同設計的並行推理架構;其次,他們還加入了量化和自定義內核等優化方法。
專屬優化:讓模型「自己跑得順」
我們知道,要構建一個高效的推理系統,必須解決兩個關鍵問題,一是計算與通信的協調,二是 KV 緩存的讀寫和存儲。
針對第一個挑戰,現有的方法通常在三個常規粒度上利用並行性:算子級的重疊、專家級的重疊以及層級的重疊。LongCat-Flash 的 ScMoE 架構引入了第四個維度 —— 模組級的重疊。為此,團隊設計了SBO(Single Batch Overlap)調度策略以優化延遲和吞吐量。
SBO 是一個四階段的流水線執行方式,通過模組級重疊充分發揮了 LongCat-Flash 的潛力,如圖 9 所示。SBO 與 TBO 的不同之處在於將通信開銷隱藏在單個批次內。它在第一階段執行 MLA 計算,為後續階段提供輸入;第二階段將 Dense FFN 和 Attn 0(QKV 投影)與 all-to-all dispatch 通信重疊;第三階段獨立執行 MoE GEMM,其延遲受益於廣泛的 EP 部署策略;第四階段將 Attn 1(核心注意力和輸出投影)及 Dense FFN 與 all-to-all combine 重疊。這種設計有效緩解了通信開銷,確保了 LongCat-Flash 的高效推理。
對於第二個挑戰 ——KV 緩存的讀寫和存儲 ——LongCat-Flash 通過其注意力機制和 MTP 結構的架構創新來解決這些問題,以減少有效的 I/O 開銷。
首先是推測解碼加速。LongCat-Flash 將 MTP 作為草稿模型,通過系統分析推測解碼的加速公式來優化三個關鍵因素:預期接受長度、草稿與目標模型的成本比以及目標驗證與解碼的成本比。通過集成單個 MTP 頭並在預訓練後期引入,實現了約 90% 的接受率。為了平衡草稿質量和速度,採用輕量級 MTP 架構減少參數,同時使用 C2T 方法通過分類模型過濾不太可能被接受的 token。
其次是 KV 緩存優化,通過 MLA 的 64 頭注意力機制實現。MLA 在保持性能和效率平衡的同時,顯著減少了計算負載並實現了出色的 KV 緩存壓縮,降低了存儲和帶寬壓力。這對於協調 LongCat-Flash 的流水線至關重要,因為模型始終具有無法與通信重疊的注意力計算。
系統級優化:讓硬體「團隊協作」
為了最小化調度開銷,LongCat-Flash 研究團隊解決了 LLM 推理系統中由內核啟動開銷導致的 launch-bound 問題。特別是在引入推測解碼後,驗證內核和草稿前向傳遞的獨立調度會產生顯著開銷。通過 TVD 融合策略,他們將目標前向、驗證和草稿前向融合到單個 CUDA 圖中。為進一步提高 GPU 利用率,他們實現了重疊調度器,並引入多步重疊調度器在單次調度迭代中啟動多個前向步驟的內核,有效隱藏 CPU 調度和同步開銷。
自定義內核優化針對 LLM 推理的自回歸特性帶來的獨特效率挑戰。預填充階段是計算密集型的,而解碼階段由於流量模式產生的小而不規則的批次大小往往是受內存限制的。對於 MoE GEMM,他們採用 SwapAB 技術將權重視為左手矩陣、激活視為右手矩陣,利用 n 維度 8 元素粒度的靈活性最大化張量核心利用率。通信內核利用 NVLink Sharp 的硬體加速廣播和 in-switch reduction 來最小化數據移動和 SM 佔用率,僅使用 4 個線程塊就在 4KB 到 96MB 訊息大小範圍內持續超越 NCCL 和 MSCCL++。
量化方面,LongCat-Flash 採用與 DeepSeek-V3 相同的細粒度塊級量化方案。為實現最佳性能 - 準確率權衡,它基於兩種方案實施了層級混合精度量化:第一種方案識別出某些線性層(特別是 Downproj)的輸入激活具有達到 10^6 的極端幅度;第二種方案逐層計算塊級 FP8 量化誤差,發現特定專家層中存在顯著量化誤差。通過取兩種方案的交集,實現了顯著的準確率提升。
實戰數據:能跑多快?多便宜?
實測性能顯示,LongCat-Flash 在不同設置下表現出色。與 DeepSeek-V3 相比,在相似的上下文長度下,LongCat-Flash 實現了更高的生成吞吐量和更快的生成速度。
在 Agent 應用中,考慮到推理內容(用戶可見,需匹配人類閱讀速度約 20 tokens/s)和動作命令(用戶不可見但直接影響工具調用啟動時間,需要最高速度)的差異化需求,LongCat-Flash 的近100 tokens/s 生成速度將單輪工具調用延遲控制在1 秒以內,顯著提升了 Agent 應用的互動性。在 H800 GPU 每小時 2 美元的成本假設下,這意味著每百萬輸出 token 的價格為 0.7 美元。
理論性能分析表明,LongCat-Flash 的延遲主要由三個組件決定:MLA、all-to-all dispatch/combine 以及 MoE。在 EP=128、每卡 batch=96、MTP 接受率≈80% 等假設下,LongCat-Flash 的理論極限 TPOT 為 16ms,相比 DeepSeek-V3 的 30ms 和 Qwen3-235B-A22B 的 26.2ms 有顯著優勢。在 H800 GPU 每小時 2 美元的成本假設下,LongCat-Flash 輸出成本為每百萬 token 0.09 美元,遠低於 DeepSeek-V3 的 0.17 美元。不過,這些數值僅為理論極限。
在 LongCat-Flash 的免費體驗頁面,我們也測試了一下。
我們首先讓這個大模型寫一篇關於秋天的文章,1000 字左右。
我們剛提出要求,剛點開錄屏,LongCat-Flash 就把答案寫出來了,錄屏都沒來得及第一時間關。
細細觀察你會發現,LongCat-Flash 的首個 token 輸出速度特別快。以往使用其他對話模型的時候,經常會遇到轉圈圈等待,非常考驗用戶耐心,就像你著急看微信,結果手機信號顯示「收取中」一樣。LongCat-Flash 改變了這一步的體驗,基本感覺不到首個 token 的延遲。
後續的 token 生成速度也很快,遠遠超出人眼的閱讀速度。
接下來,我們打開「聯網搜索」,看看 LongCat-Flash 這項能力夠不夠快。我們讓 LongCat-Flash 推薦望京附近好吃的餐廳。
測試下來可以明顯感受到,LongCat-Flash 並不是思考半天才慢悠悠地開口,而是幾乎立刻就能給出答案。聯網搜索給人的感受也是「快」。不僅如此,它在快速輸出的同時還能附帶引用來源,讓信息的可信度與可追溯性都有保障。
有條件下載模型的讀者可以在自己本地跑一下,看看 LongCat-Flash 的速度是否同樣驚艷。
當大模型走進實用時代
過去幾年,每當出來一個大模型,大家都會關心:它的 benchmark 數據是多少?刷新了多少個榜單?是不是 SOTA?如今,情況已經發生了變化。在能力差不多的情況下,大家更關心:你這個模型用起來貴不貴?速度怎麼樣?在使用開源模型的企業和開發者中,這種情況尤其明顯。因為很多用戶用開源模型就是為了降低對閉源 API 的依賴和費用,所以對算力需求、推理速度、壓縮量化效果更敏感。
美團開源的 LongCat-Flash 正是順應這種趨勢的代表作。他們把重點放在了怎麼讓大模型真正用得起、跑得快,這是一項技術普及的關鍵。
這種實用路線的選擇和我們對美團一直以來的觀感是一致的。過去,他們在技術上的絕大部分投入都用來解決真實業務痛點,比如 2022 年獲 ICRA 最佳導航論文的 EDPLVO,其實就是為了解決無人機在配送途中遇到的各種意外情況(比如樓宇過密會失去信號);最近參與制訂的全球無人機避障 ISO 標準,是無人機在飛行途中躲避風箏線、擦玻璃安全繩等案例的技術經驗沉澱。而這次開源的 LongCat-Flash 其實是他們的 AI 編程類工具「NoCode」背後的模型,這個工具既服務於公司內部,也對外免費開放,就是希望大家能把 vibe coding 用起來,實現降本增效。
這種從性能競賽向實用導向的轉變,其實反映了 AI 行業發展的自然規律。當模型能力逐漸趨同時,工程效率和部署成本就成了關鍵差異化因素。LongCat-Flash 的開源只是這個趨勢中的一個案例,但它確實為社群提供了一個可參考的技術路徑:如何在保持模型質量的前提下,通過架構創新和系統優化來降低使用門檻。這對於那些預算有限但又希望用上先進 AI 能力的開發者和企業來說,無疑是有價值的。
免責聲明:文章中的所有內容僅代表作者的觀點,與本平台無關。用戶不應以本文作為投資決策的參考。
您也可能喜歡
關於 Bitget 與 Morph 公鏈達成戰略合作及 BGB 定位升級的公告

NBER | 用模型揭示數字經濟擴張如何重塑全球金融格局
研究結果顯示,從長期來看,儲備需求效應主導了替代效應,導致美國利率下降,美國對外借款增加。

ETH接管舞台:牛市下半場的真正開幕
綜合市場結構、資金流向、鏈上數據以及政策環境,我們的判斷十分明確:以太坊正逐步取代比特幣,成為牛市下半場的核心資產。
