
Vitalik: Nova concepção de arquitetura de colagem e coprocessador para aumentar a efici�ência e a segurança

O aglutinador deve ser otimizado para ser um bom aglutinador, enquanto o coprocessador também deve ser otimizado para ser um bom coprocessador.
O "glue" deve ser otimizado para ser um bom "glue", enquanto o coprocessador também deve ser otimizado para ser um bom coprocessador.
Título original: "Glue and coprocessor architectures"
Autor: Vitalik Buterin, fundador da Ethereum
Tradução: Deng Tong, Jinse Finance
Agradecimentos especiais a Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra e vários colaboradores da Flashbots pelos feedbacks e comentários.
Se você analisar com um nível médio de detalhe qualquer computação intensiva em recursos no mundo moderno, encontrará repetidamente uma característica: a computação pode ser dividida em duas partes:
- Uma quantidade relativamente pequena de "lógica de negócios" complexa, mas não intensiva em computação;
- Uma grande quantidade de "trabalho caro" intensivo, mas altamente estruturado.
Essas duas formas de computação são melhor tratadas de maneiras diferentes: a primeira pode ter uma arquitetura menos eficiente, mas precisa ser altamente genérica; a segunda pode ter uma arquitetura menos genérica, mas precisa ser extremamente eficiente.
Quais são os exemplos práticos dessas abordagens diferentes?
Primeiro, vamos olhar para o ambiente com o qual estou mais familiarizado: a Ethereum Virtual Machine (EVM). Aqui está um rastreamento de depuração geth de uma transação Ethereum que fiz recentemente: atualizando o hash IPFS do meu blog no ENS. Essa transação consumiu um total de 46.924 gas, que pode ser categorizado da seguinte forma:
- Custo básico: 21.000
- Dados de chamada: 1.556
- Execução EVM: 24.368
- Opcode SLOAD: 6.400
- Opcode SSTORE: 10.100
- Opcode LOG: 2.149
- Outros: 6.719

Rastreamento EVM da atualização do hash ENS. A penúltima coluna mostra o consumo de gas.
A moral da história é: a maior parte da execução (cerca de 73% se considerarmos apenas a EVM, ou cerca de 85% se incluirmos a parte do custo básico que cobre a computação) está concentrada em um pequeno número de operações caras e estruturadas: leituras e gravações de armazenamento, logs e criptografia (o custo básico inclui 3.000 para pagar pela verificação de assinatura, e a EVM inclui mais 272 para pagar pelo hash). O restante da execução é "lógica de negócios": trocar bits de calldata para extrair o ID do registro que estou tentando definir e o hash para o qual estou definindo, etc. Em transferências de tokens, isso incluiria adicionar e subtrair saldos; em aplicativos mais avançados, pode incluir loops, etc.
Na EVM, essas duas formas de execução são tratadas de maneiras diferentes. A lógica de negócios de alto nível é escrita em linguagens de alto nível, geralmente Solidity, que pode ser compilada para EVM. O trabalho caro ainda é acionado por opcodes da EVM (como SLOAD), mas mais de 99% da computação real é feita em módulos especializados escritos diretamente no código do cliente (ou até mesmo em bibliotecas).
Para reforçar a compreensão desse padrão, vamos explorá-lo em outro contexto: código de IA escrito em Python usando torch.
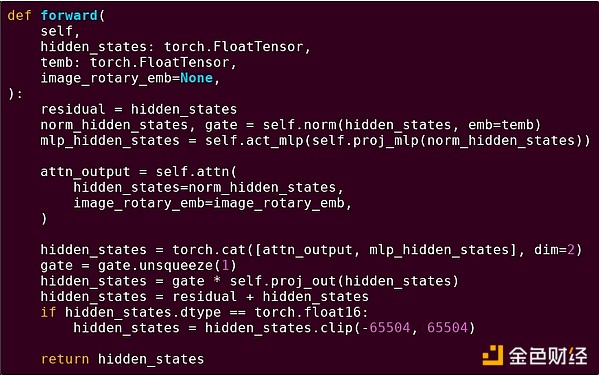
Forward pass de um bloco de modelo transformer
O que vemos aqui? Vemos uma quantidade relativamente pequena de "lógica de negócios" escrita em Python, que descreve a estrutura das operações sendo executadas. Na prática, também haverá outro tipo de lógica de negócios, que decide detalhes como como obter a entrada e o que fazer com a saída. Mas, se olharmos mais de perto para cada operação individual (self.norm, torch.cat, +, *, as etapas internas de self.attn...), veremos computação vetorizada: a mesma operação sendo computada em paralelo para muitos valores. Assim como no primeiro exemplo, uma pequena parte da computação é para lógica de negócios, enquanto a maior parte é para executar grandes operações estruturadas de matrizes e vetores — na verdade, a maioria é apenas multiplicação de matrizes.
Assim como no exemplo da EVM, esses dois tipos de trabalho são tratados de maneiras diferentes. O código de lógica de negócios de alto nível é escrito em Python, uma linguagem altamente genérica e flexível, mas também muito lenta; aceitamos a ineficiência porque ela envolve apenas uma pequena parte do custo computacional total. Enquanto isso, as operações intensivas são escritas em código altamente otimizado, geralmente rodando em CUDA no GPU. Estamos vendo cada vez mais inferência de LLM rodando em ASICs.
A criptografia programável moderna, como SNARK, segue novamente um padrão semelhante em dois níveis. Primeiro, o provador pode ser escrito em uma linguagem de alto nível, onde o trabalho pesado é feito por operações vetorizadas, assim como no exemplo de IA acima. Meu código circular STARK mostra isso aqui. Em segundo lugar, o próprio programa executado dentro da criptografia pode ser escrito de uma forma que separe a lógica de negócios genérica do trabalho caro e altamente estruturado.
Para entender como isso funciona, podemos olhar para uma das tendências recentes nas provas STARK. Para serem genéricos e fáceis de usar, as equipes estão cada vez mais construindo provadores STARK para as menores máquinas virtuais amplamente adotadas (como RISC-V). Qualquer programa que precise de prova de execução pode ser compilado para RISC-V, e então o provador pode provar a execução desse código em RISC-V.
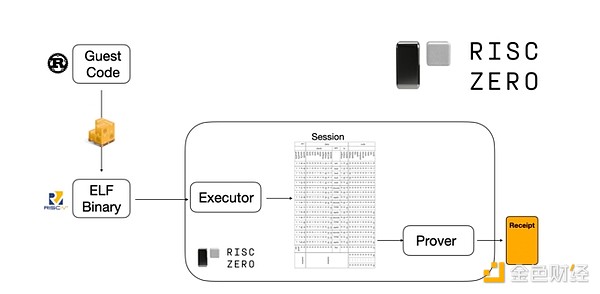
Gráfico da documentação da RiscZero
Isso é muito conveniente: significa que só precisamos escrever a lógica de prova uma vez, e a partir daí, qualquer programa que precise de prova pode ser escrito em qualquer linguagem de programação "tradicional" (por exemplo, RiskZero suporta Rust). Mas há um problema: esse método gera muita sobrecarga. A criptografia programável já é muito cara; adicionar a sobrecarga de rodar o código em um interpretador RISC-V é demais. Então, os desenvolvedores inventaram um truque: identificar operações caras específicas que compõem a maior parte da computação (geralmente hashes e assinaturas), e então criar módulos especializados para provar essas operações de forma muito eficiente. Assim, basta combinar o sistema de provas RISC-V, que é ineficiente mas genérico, com sistemas de prova eficientes mas especializados, para obter o melhor dos dois mundos.
Criptografia programável além de ZK-SNARK, como computação multipartidária (MPC) e criptografia totalmente homomórfica (FHE), pode ser otimizada de maneira semelhante.
De modo geral, como é esse fenômeno?
A computação moderna segue cada vez mais o que chamo de arquitetura "glue e coprocessador": você tem alguns componentes centrais de "glue", altamente genéricos mas ineficientes, responsáveis por transferir dados entre um ou mais componentes coprocessadores, que são pouco genéricos mas altamente eficientes.
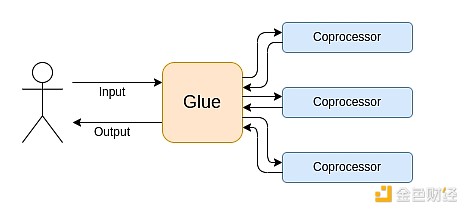
Isso é uma simplificação: na prática, a curva de trade-off entre eficiência e generalidade quase sempre tem mais de dois níveis. GPUs e outros chips normalmente chamados de "coprocessadores" na indústria são menos genéricos que CPUs, mas mais genéricos que ASICs. O trade-off do grau de especialização é complexo, dependendo de previsões e intuições sobre quais partes do algoritmo permanecerão as mesmas em cinco anos e quais mudarão em seis meses. Na arquitetura de provas ZK, frequentemente vemos especialização em múltiplos níveis. Mas para um modelo mental amplo, considerar dois níveis é suficiente. Em muitos campos da computação, há situações semelhantes:
Pelos exemplos acima, a computação certamente pode ser dividida dessa forma, e isso parece ser uma lei natural. Na verdade, você pode encontrar exemplos de especialização computacional há décadas. No entanto, acredito que essa separação está aumentando. E há razões para isso:
Somente recentemente atingimos o limite do aumento da velocidade do clock da CPU, então só é possível obter ganhos adicionais por meio de paralelização. Mas a paralelização é difícil de raciocinar, então para os desenvolvedores, muitas vezes é mais prático continuar raciocinando sequencialmente e deixar a paralelização acontecer no backend, encapsulada em módulos especializados construídos para operações específicas.
A velocidade de computação só recentemente se tornou tão alta que o custo computacional da lógica de negócios realmente se tornou negligenciável. Nesse mundo, faz sentido otimizar a VM que executa a lógica de negócios para objetivos além da eficiência computacional: facilidade de desenvolvimento, familiaridade, segurança e outros objetivos semelhantes. Ao mesmo tempo, módulos especializados de "coprocessador" podem continuar a ser projetados para eficiência, obtendo segurança e facilidade de desenvolvimento de sua interface relativamente simples com o glue.
Quais são as operações caras mais importantes está se tornando cada vez mais claro. Isso é mais evidente na criptografia, onde é mais provável que certos tipos de operações caras sejam usados: operações modulares, combinações lineares de curvas elípticas (também conhecidas como multiplicação multiescalar), transformadas rápidas de Fourier, etc. Em IA, isso também está cada vez mais claro: por mais de vinte anos, a maior parte da computação tem sido "principalmente multiplicação de matrizes" (embora com diferentes níveis de precisão). Outras áreas também mostram tendências semelhantes. Em comparação com vinte anos atrás, há muito menos incógnitas (desconhecidos desconhecidos) em computação intensiva.
O que isso significa?
Um ponto-chave é que o glue deve ser otimizado para ser um bom glue, enquanto o coprocessador deve ser otimizado para ser um bom coprocessador. Podemos explorar o significado disso em algumas áreas-chave.
EVM
Máquinas virtuais de blockchain (como a EVM) não precisam ser eficientes, apenas familiares. Basta adicionar os coprocessadores certos (também conhecidos como "precompilados"), e a computação em uma VM ineficiente pode ser tão eficiente quanto em uma VM nativamente eficiente. Por exemplo, a sobrecarga dos registradores de 256 bits da EVM é relativamente pequena, enquanto os benefícios da familiaridade da EVM e do ecossistema de desenvolvedores existente são enormes e duradouros. Equipes que otimizam a EVM até descobriram que a falta de paralelização geralmente não é o principal obstáculo à escalabilidade.
A melhor maneira de melhorar a EVM pode ser simplesmente (i) adicionar melhores precompilados ou opcodes especializados — por exemplo, alguma combinação de EVM-MAX e SIMD pode ser razoável — e (ii) melhorar o layout de armazenamento, por exemplo, mudanças nas árvores Verkle que, como efeito colateral, reduzem muito o custo de acessar slots de armazenamento adjacentes.
Otimização de armazenamento na proposta de árvore Verkle da Ethereum, agrupando chaves de armazenamento adjacentes e ajustando o custo de gas para refletir isso. Otimizações como essa, junto com melhores precompilados, podem ser mais importantes do que ajustes na própria EVM.
Computação segura e hardware aberto
Um grande desafio para aumentar a segurança da computação moderna no nível de hardware é sua natureza excessivamente complexa e proprietária: chips são projetados para serem eficientes, o que exige otimizações proprietárias. Backdoors são fáceis de esconder, e vulnerabilidades de canal lateral são constantemente descobertas.
As pessoas continuam trabalhando de vários ângulos para promover alternativas mais abertas e seguras. Algumas computações são cada vez mais realizadas em ambientes de execução confiáveis, incluindo no telefone do usuário, o que já aumentou a segurança do usuário. O movimento para hardware de consumo mais open source continua, com algumas vitórias recentes, como laptops RISC-V rodando Ubuntu.
Laptop RISC-V rodando Debian
No entanto, a eficiência ainda é um problema. O autor do artigo linkado acima escreveu:
Projetos de chips open source mais recentes, como RISC-V, não podem competir com tecnologias de processadores já existentes e aprimoradas por décadas. Todo progresso tem um ponto de partida.
Ideias mais paranoicas, como este design de computador RISC-V construído em FPGA, enfrentam ainda mais sobrecarga. Mas e se a arquitetura glue e coprocessador significar que essa sobrecarga realmente não importa? E se aceitarmos que chips abertos e seguros serão mais lentos que chips proprietários, e até mesmo abrirmos mão de otimizações comuns como execução especulativa e predição de ramificação, mas tentarmos compensar isso adicionando módulos ASIC (proprietários, se necessário) para os tipos mais intensivos de computação? A computação sensível pode ser feita no "chip principal", otimizado para segurança, design open source e resistência a canais laterais. Computações mais intensivas (como provas ZK, IA) seriam feitas em módulos ASIC, que saberiam menos sobre a computação executada (talvez, por meio de ofuscação criptográfica, em alguns casos até zero conhecimento).
Criptografia
Outro ponto-chave é que tudo isso é muito otimista para a criptografia, especialmente para a criptografia programável se tornar mainstream. Já vimos algumas implementações super otimizadas de cálculos altamente estruturados em SNARK, MPC e outros cenários: o overhead de certos hashes é apenas algumas centenas de vezes mais caro que rodar o cálculo diretamente, e o overhead para IA (principalmente multiplicação de matrizes) também é muito baixo. Melhorias como GKR podem reduzir ainda mais esse nível. Execução de VM totalmente genérica, especialmente quando executada em um interpretador RISC-V, pode continuar tendo um overhead de cerca de dez mil vezes, mas por razões descritas neste artigo, isso não importa: desde que as partes mais intensivas da computação sejam tratadas separadamente com técnicas especializadas eficientes, o overhead total é controlável.
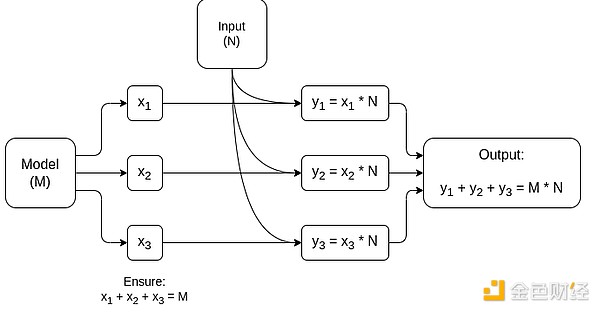
Diagrama simplificado de MPC especializado em multiplicação de matrizes, o maior componente da inferência de modelos de IA. Veja este artigo para mais detalhes, incluindo como manter a privacidade do modelo e das entradas.
Uma exceção à ideia de que "a camada glue só precisa ser familiar, não eficiente" é a latência, e em menor grau, a largura de banda de dados. Se a computação envolve operações pesadas repetidas dezenas de vezes nos mesmos dados (como em criptografia e IA), qualquer latência causada por uma camada glue ineficiente pode se tornar o principal gargalo do tempo de execução. Portanto, a camada glue também tem requisitos de eficiência, embora mais específicos.
Conclusão
No geral, acredito que as tendências acima são desenvolvimentos muito positivos sob várias perspectivas. Primeiro, é uma maneira razoável de maximizar a eficiência computacional mantendo a facilidade de desenvolvimento, permitindo obter mais de ambos, o que beneficia a todos. Em particular, ao implementar especialização no lado do cliente para aumentar a eficiência, aumenta nossa capacidade de executar localmente no hardware do usuário cálculos sensíveis e de alto desempenho (como provas ZK, inferência LLM). Em segundo lugar, cria uma enorme janela de oportunidade para garantir que a busca por eficiência não prejudique outros valores, principalmente segurança, abertura e simplicidade: segurança e abertura contra canais laterais em hardware de computador, redução da complexidade de circuitos em ZK-SNARKs e redução da complexidade em máquinas virtuais. Historicamente, a busca por eficiência relegou esses outros fatores a segundo plano. Com a arquitetura glue e coprocessador, isso não é mais necessário. Uma parte da máquina é otimizada para eficiência, a outra para generalidade e outros valores, e ambas trabalham juntas.
Essa tendência também é muito favorável para a criptografia, pois a própria criptografia é um grande exemplo de "cálculo estruturado caro", e essa tendência acelera seu desenvolvimento. Isso cria mais uma oportunidade para aumentar a segurança. No mundo blockchain, o aumento da segurança também se torna possível: podemos nos preocupar menos com a otimização da máquina virtual e focar mais em otimizar precompilados e outras funcionalidades que coexistem com a VM.
Terceiro, essa tendência oferece oportunidades para participantes menores e mais novos. Se a computação se tornar menos monolítica e mais modular, isso reduzirá muito a barreira de entrada. Mesmo ASICs para um tipo de computação podem fazer a diferença. Isso também vale para provas ZK e otimização da EVM. Escrever código com eficiência quase de ponta se torna mais fácil e acessível. Auditar e formalizar a verificação desse tipo de código também se torna mais fácil e acessível. Por fim, como esses campos de computação muito diferentes estão convergindo para alguns padrões comuns, há mais espaço para colaboração e aprendizado entre eles.
Aviso Legal: o conteúdo deste artigo reflete exclusivamente a opinião do autor e não representa a plataforma. Este artigo não deve servir como referência para a tomada de decisões de investimento.
Talvez também goste
JPMorgan prevê que as stablecoins não alcançarão US$ 1 trilhão até 2028
Promotor sênior do esquema ponzi de criptomoedas IcomTech é condenado a seis anos de prisão
XRP está acariciando sua base de suporte de 13 meses. Veja o significado disso