
En tête des tendances ! Le grand modèle de Meituan devient populaire grâce à sa rapidité

Développeurs nationaux et internationaux : testé personnellement, le nouveau modèle open source de Meituan est ultra-rapide !
Lorsque l’IA deviendra vraiment aussi omniprésente que l’eau et l’électricité, la puissance du modèle ne sera plus la seule préoccupation.
Depuis le début de l’année avec Claude 3.7 Sonnet, Gemini 2.5 Flash, jusqu’aux récents GPT-5 et DeepSeek V3.1, tous les leaders du secteur réfléchissent à la même question : comment, tout en garantissant la précision, permettre à l’IA de résoudre chaque problème avec un minimum de puissance de calcul et de répondre dans les délais les plus courts ? En d’autres termes, comment éviter de gaspiller des tokens et du temps.
Pour les entreprises et développeurs qui construisent des applications sur ces modèles, ce passage de la « simple construction du modèle le plus puissant » à celle de modèles plus pratiques et plus rapides est une excellente nouvelle. Encore mieux, de plus en plus de modèles open source émergent dans ce domaine.
Il y a quelques jours, nous avons découvert un nouveau modèle sur HuggingFace : LongCat-Flash-Chat.

Ce modèle fait partie de la série LongCat-Flash de Meituan, utilisable directement sur le site officiel.
Il comprend naturellement que « tous les tokens ne se valent pas » et attribue donc dynamiquement des budgets de calcul plus importants aux tokens les plus importants. Cela lui permet, tout en n’activant qu’un petit nombre de paramètres, d’atteindre des performances comparables aux meilleurs modèles open source actuels.

Après son ouverture en open source, LongCat-Flash est devenu un sujet tendance.
Par ailleurs, la vitesse de ce modèle a également impressionné tout le monde : sur une carte graphique H800, la vitesse d’inférence dépasse 100 tokens par seconde. Les tests de développeurs du monde entier le confirment : certains ont atteint 95 tokens/s, d’autres ont obtenu des réponses comparables à Claude en un temps record.
Source : utilisateur Zhihu @小小将.
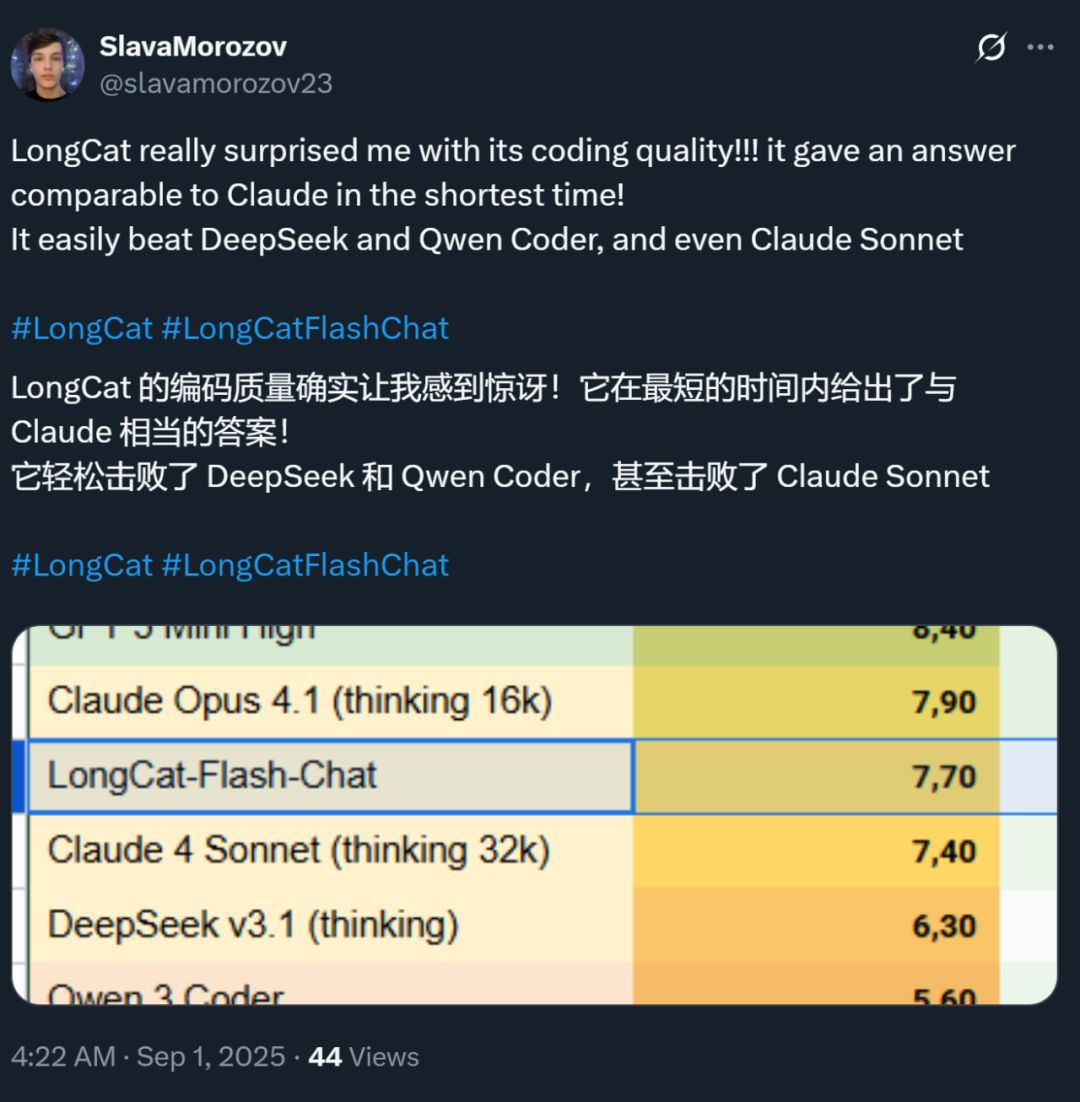
Source : utilisateur X @SlavaMorozov.
En même temps que la mise en open source du modèle, Meituan a également publié le rapport technique de LongCat-Flash, dans lequel de nombreux détails techniques sont exposés.

Rapport technique : LongCat-Flash Technical Report
Dans cet article, nous allons détailler ces aspects.
Comment économiser de la puissance de calcul avec les grands modèles ?
Regardons les innovations architecturales et les méthodes d’entraînement de LongCat-Flash
LongCat-Flash est un modèle à experts mixtes avec un total de 560 milliards de paramètres, capable d’activer de 18,6 à 31,3 milliards (en moyenne 27 milliards) de paramètres selon le contexte.
Le modèle a été entraîné sur plus de 20 000 milliards de tokens, mais le temps d’entraînement n’a été que de moins de 30 jours. Pendant cette période, le système a atteint un taux de disponibilité de 98,48 %, nécessitant presque aucune intervention humaine pour gérer les pannes — ce qui signifie que l’ensemble du processus d’entraînement a été pratiquement « sans intervention humaine ».
Encore plus impressionnant, ce modèle ainsi entraîné est tout aussi performant lors du déploiement réel.
Comme illustré ci-dessous, en tant que modèle non réflexif, LongCat-Flash atteint des performances comparables aux meilleurs modèles non réflexifs SOTA, tels que DeepSeek-V3.1 et Kimi-K2, tout en utilisant moins de paramètres et en offrant une vitesse d’inférence supérieure. Cela le rend très compétitif et pratique dans des domaines tels que l’utilisation générale, la programmation et les outils d’agents intelligents.
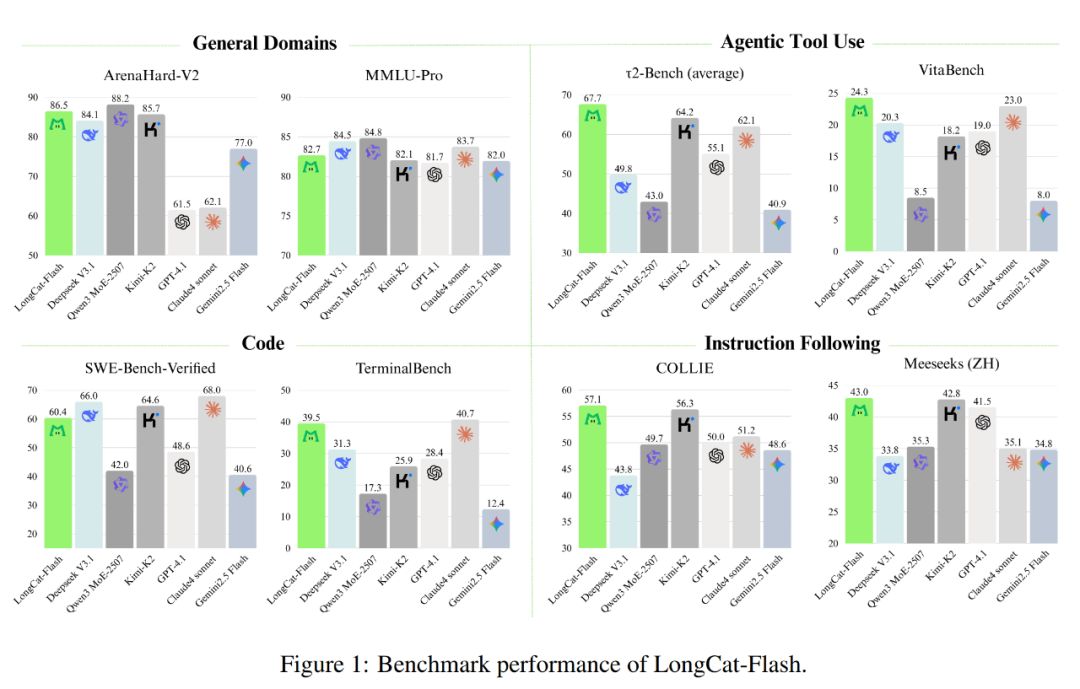
De plus, son coût est remarquable, à seulement 0,7 dollar par million de tokens générés. Ce prix est très compétitif par rapport aux modèles de taille équivalente sur le marché.
D’un point de vue technique, LongCat-Flash vise principalement deux objectifs pour les modèles de langage : l’efficacité de calcul et la capacité d’agent, en combinant innovations architecturales et méthodes d’entraînement multi-étapes pour créer un système de modèles intelligent et extensible.
Au niveau de l’architecture, LongCat-Flash adopte une nouvelle architecture MoE (figure 2), avec deux points forts :
Experts à zéro calcul (Zero-computation Experts) ;
MoE à connexion rapide (Shortcut-connected MoE, ScMoE).
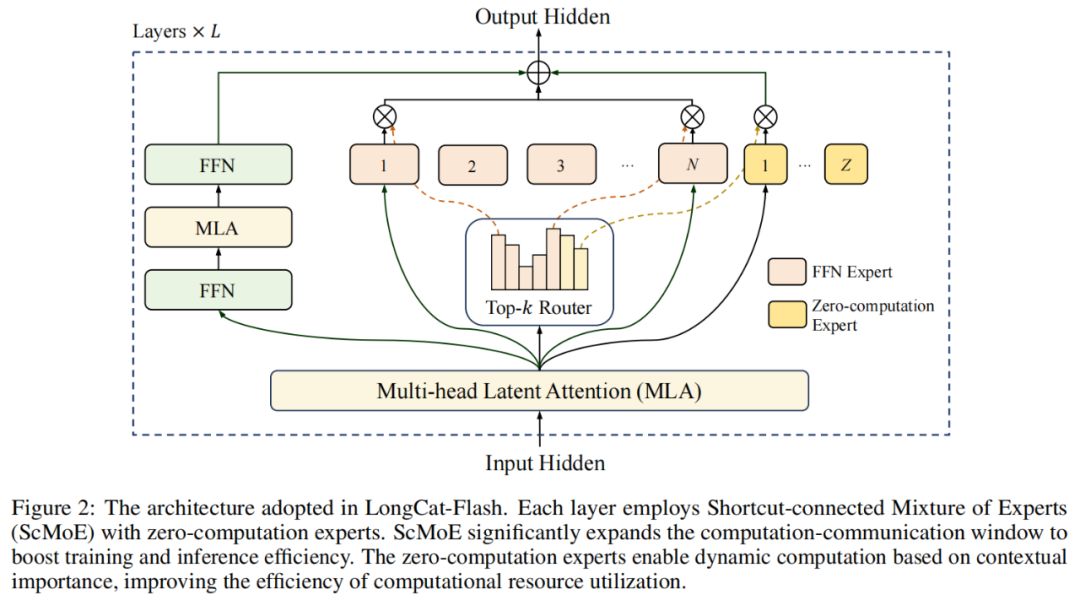
Experts à zéro calcul
L’idée centrale des experts à zéro calcul est que tous les tokens ne sont pas « égaux ».
On peut le comprendre ainsi : dans une phrase, certains mots sont très faciles à prédire, comme « de », « est », et ne nécessitent presque aucun calcul, alors que d’autres, comme les noms propres, nécessitent beaucoup de calculs pour être prédits correctement.
Dans les recherches précédentes, la méthode courante consistait à activer un nombre fixe (K) d’experts pour chaque token, qu’il soit simple ou complexe, ce qui entraînait un énorme gaspillage de calcul. Pour les tokens simples, il n’est pas nécessaire d’appeler autant d’experts, tandis que pour les tokens complexes, il peut manquer de ressources de calcul.
Inspiré par cela, LongCat-Flash propose un mécanisme de répartition dynamique des ressources de calcul : grâce aux experts à zéro calcul, il active dynamiquement un nombre différent d’experts FFN (Feed-Forward Network) pour chaque token, répartissant ainsi plus rationnellement la charge de calcul selon l’importance contextuelle.
Concrètement, dans le pool d’experts de LongCat-Flash, en plus des N experts FFN standards, Z experts à zéro calcul sont ajoutés. Ces experts renvoient simplement l’entrée telle quelle en sortie, sans coût de calcul supplémentaire.
Le module MoE de LongCat-Flash peut être formalisé ainsi :
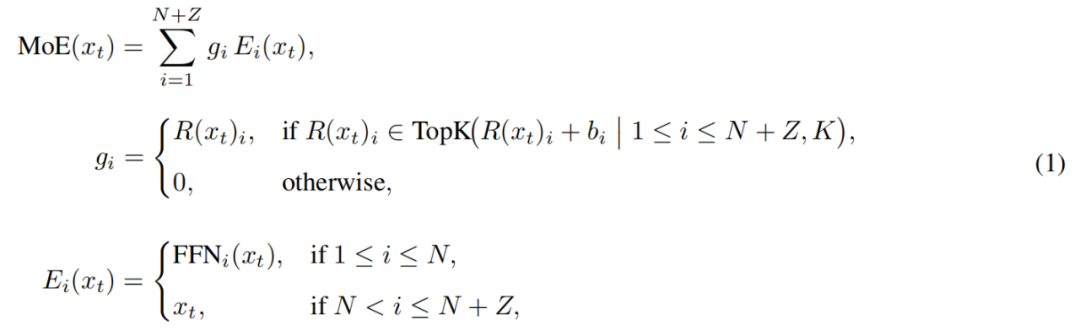
Où x_t est le t-ème token de la séquence d’entrée, R représente le routeur softmax, b_i le biais de l’expert i, et K le nombre d’experts sélectionnés pour chaque token. Le routeur attribue chaque token à K experts, le nombre d’experts FFN activés variant selon l’importance contextuelle du token. Ce mécanisme adaptatif permet au modèle d’allouer dynamiquement plus de ressources de calcul aux tokens les plus importants, obtenant ainsi de meilleures performances à charge de calcul égale, comme illustré en figure 3a.
Par ailleurs, lors du traitement des entrées, le modèle doit apprendre à décider, selon l’importance du token, s’il faut ou non allouer plus de ressources de calcul. Sans contrôle de la fréquence de sélection des experts à zéro calcul, le modèle pourrait privilégier les experts calculants et négliger les experts à zéro calcul, réduisant ainsi l’efficacité des ressources.
Pour résoudre ce problème, Meituan a amélioré le mécanisme de biais d’expert dans la stratégie aux-loss-free : en introduisant un biais spécifique à chaque expert, ajusté dynamiquement selon l’utilisation récente de l’expert, tout en restant découplé de l’objectif d’entraînement du modèle de langage.
La règle de mise à jour utilise un contrôleur PID issu de la théorie du contrôle pour ajuster en temps réel le biais des experts. Grâce à cela, lors du traitement de chaque token, le modèle n’a besoin d’activer que 18,6 à 31,3 milliards de paramètres (la moyenne étant d’environ 27 milliards), optimisant ainsi l’allocation des ressources.
MoE à connexion rapide
L’autre innovation de LongCat-Flash est le mécanisme MoE à connexion rapide.
En général, l’efficacité des grands modèles MoE est largement limitée par les coûts de communication. Dans le paradigme d’exécution traditionnel, le parallélisme des experts introduit un flux de travail séquentiel : il faut d’abord effectuer une communication globale pour router les tokens vers leurs experts respectifs, puis seulement commencer le calcul.
Cette séquence communication-puis-calcul engendre des temps d’attente supplémentaires, surtout dans l’entraînement distribué à grande échelle, où la latence de communication devient un goulot d’étranglement.
Des chercheurs ont tenté d’atténuer ce problème via une architecture d’experts partagés, en superposant la communication et le calcul d’un expert unique, mais l’efficacité est limitée par la petite taille de la fenêtre de calcul de chaque expert.
Meituan surmonte cette limite en introduisant l’architecture ScMoE, qui ajoute une connexion rapide inter-couches, permettant au calcul du FFN dense de la couche précédente de s’exécuter en parallèle avec la communication de dispatch/agrégation de la couche MoE actuelle. Par rapport à l’architecture à experts partagés, cela crée une fenêtre de superposition communication-calcul beaucoup plus large.
Cette conception a été validée par de nombreuses expériences.
Premièrement, la conception ScMoE ne dégrade pas la qualité du modèle. Comme le montre la figure 4, la courbe de perte à l’entraînement du modèle avec ScMoE est quasiment identique à celle du modèle de référence sans ScMoE, prouvant que ce réordonnancement de l’exécution ne nuit pas aux performances. Ce constat est confirmé dans diverses configurations.
Plus important encore, ces résultats montrent que la stabilité et les avantages de performance de ScMoE sont orthogonaux au choix du mécanisme d’attention (c’est-à-dire qu’ils restent constants quel que soit le mécanisme d’attention utilisé).
Deuxièmement, l’architecture ScMoE apporte d’importants gains d’efficacité système pour l’entraînement et l’inférence. Concrètement :
Pour l’entraînement à grande échelle : la fenêtre de superposition élargie permet au calcul du bloc précédent de s’exécuter entièrement en parallèle avec la communication de dispatch et d’agrégation de la couche MoE, grâce à une partition fine des opérations selon la dimension token.
Pour l’inférence efficace : ScMoE prend en charge le pipeline de superposition sur un seul batch, réduisant de près de 50 % le temps théorique par token (TPOT) par rapport à des modèles leaders comme DeepSeek-V3. Plus important encore, il permet l’exécution simultanée de différents modes de communication : la communication intra-nœud sur le FFN dense (via NVLink) peut se superposer entièrement à la communication inter-nœuds des experts (via RDMA), maximisant ainsi l’utilisation du réseau.
En résumé, ScMoE offre d’importants gains de performance sans sacrifier la qualité du modèle.
Stratégie d’extension du modèle et entraînement multi-étapes
Meituan a également proposé une stratégie d’extension efficace du modèle pour améliorer significativement les performances à grande échelle.
Premièrement, le transfert d’hyperparamètres : entraîner un modèle de très grande taille en testant directement diverses configurations d’hyperparamètres est coûteux et instable. Meituan commence donc par expérimenter sur des modèles plus petits pour trouver la meilleure combinaison d’hyperparamètres, puis transfère ces paramètres au grand modèle, économisant ainsi des coûts tout en garantissant l’efficacité. Les règles de transfert sont présentées dans le tableau 1 :
Ensuite, l’initialisation par croissance du modèle : Meituan commence par un modèle de demi-taille pré-entraîné sur des centaines de milliards de tokens, conserve le checkpoint, puis étend le modèle à sa taille complète et poursuit l’entraînement.
Avec cette méthode, la courbe de perte du modèle suit un schéma typique : une brève augmentation suivie d’une convergence rapide, aboutissant à des performances nettement supérieures à une initialisation aléatoire. La figure 5b montre un résultat représentatif de l’expérience avec 6B paramètres activés, illustrant l’avantage de cette initialisation.
Troisièmement, une suite de stabilité multi-niveaux : Meituan a renforcé la stabilité de l’entraînement de LongCat-Flash sur trois plans : stabilité du routeur, stabilité de l’activation et stabilité de l’optimiseur.
Quatrièmement, le calcul déterministe : cette méthode garantit la reproductibilité totale des résultats expérimentaux et permet de détecter les corruptions silencieuses de données (Silent Data Corruption, SDC) pendant l’entraînement.
Grâce à ces mesures, l’entraînement de LongCat-Flash reste hautement stable, sans pics de perte irréversibles.
En maintenant la stabilité de l’entraînement, Meituan a également soigneusement conçu le pipeline d’entraînement, dotant LongCat-Flash de comportements d’agent avancés, couvrant le pré-entraînement à grande échelle, l’entraînement intermédiaire axé sur le raisonnement et le code, et l’entraînement final centré sur le dialogue et l’utilisation d’outils.
Phase initiale : construire un modèle de base mieux adapté à l’entraînement ultérieur d’agents, pour laquelle Meituan a conçu une stratégie de fusion de données de pré-entraînement en deux étapes, concentrant les données sur les domaines à forte densité de raisonnement.
Phase intermédiaire : Meituan renforce les capacités de raisonnement et de code du modèle, tout en étendant la longueur du contexte à 128k pour répondre aux besoins de l’entraînement ultérieur d’agents.
Enfin, Meituan a mené un entraînement final multi-étapes. Étant donné la rareté des données d’entraînement de haute qualité et de grande difficulté dans le domaine des agents, Meituan a conçu un cadre multi-agents synthétique : ce cadre définit la difficulté des tâches selon trois dimensions — traitement de l’information, complexité de l’ensemble d’outils et interaction utilisateur — et utilise un contrôleur spécialisé pour générer des tâches complexes nécessitant un raisonnement itératif et une interaction avec l’environnement.
Cette conception permet d’exceller dans l’exécution de tâches complexes nécessitant l’appel d’outils et l’interaction avec l’environnement.
Rapide et économique à l’exécution
Comment LongCat-Flash y parvient-il ?
Comme mentionné précédemment, LongCat-Flash peut inférer à plus de 100 tokens par seconde sur une carte H800, pour un coût de seulement 0,7 dollar par million de tokens générés : rapide et économique.
Comment cela est-il possible ? D’abord, ils ont conçu une architecture d’inférence parallèle en synergie avec l’architecture du modèle ; ensuite, ils ont intégré des optimisations telles que la quantification et des noyaux personnalisés.
Optimisation dédiée : rendre le modèle « fluide par lui-même »
Pour construire un système d’inférence efficace, il faut résoudre deux problèmes clés : la coordination entre calcul et communication, et la lecture/écriture et le stockage du cache KV.
Pour le premier défi, les méthodes existantes exploitent généralement le parallélisme à trois niveaux : superposition au niveau des opérateurs, des experts et des couches. L’architecture ScMoE de LongCat-Flash introduit une quatrième dimension : la superposition au niveau des modules. Pour cela, l’équipe a conçu la stratégie d’ordonnancement SBO (Single Batch Overlap) pour optimiser la latence et le débit.
SBO est une exécution pipeline en quatre phases, exploitant pleinement la superposition au niveau des modules de LongCat-Flash, comme illustré en figure 9. La différence avec TBO est que SBO masque les coûts de communication à l’intérieur d’un seul batch. La première phase effectue le calcul MLA, fournissant l’entrée aux phases suivantes ; la deuxième phase superpose le Dense FFN et Attn 0 (projection QKV) avec la communication all-to-all dispatch ; la troisième phase exécute indépendamment le MoE GEMM, dont la latence bénéficie de la stratégie de déploiement EP ; la quatrième phase superpose Attn 1 (attention principale et projection de sortie) et Dense FFN avec la communication all-to-all combine. Cette conception atténue efficacement les coûts de communication, assurant une inférence efficace de LongCat-Flash.
Pour le second défi — lecture/écriture et stockage du cache KV — LongCat-Flash le résout par des innovations architecturales dans son mécanisme d’attention et sa structure MTP, réduisant ainsi les coûts d’I/O effectifs.
D’abord, l’accélération du décodage spéculatif. LongCat-Flash utilise MTP comme modèle de brouillon, optimisant trois facteurs clés via une analyse systémique de la formule d’accélération du décodage spéculatif : longueur d’acceptation attendue, ratio de coût entre le modèle de brouillon et le modèle cible, et ratio de coût entre la validation cible et le décodage. En intégrant une seule tête MTP et en l’introduisant en fin de pré-entraînement, un taux d’acceptation d’environ 90 % est atteint. Pour équilibrer qualité et vitesse du brouillon, une architecture MTP légère réduit les paramètres, tandis que la méthode C2T utilise un modèle de classification pour filtrer les tokens peu susceptibles d’être acceptés.
Ensuite, l’optimisation du cache KV, réalisée via le mécanisme d’attention à 64 têtes de MLA. MLA équilibre performance et efficacité tout en réduisant considérablement la charge de calcul et en offrant une excellente compression du cache KV, allégeant la pression sur le stockage et la bande passante. Ceci est crucial pour coordonner le pipeline de LongCat-Flash, car le modèle comporte toujours des calculs d’attention non superposables à la communication.
Optimisation système : faire collaborer le matériel
Pour minimiser les coûts d’ordonnancement, l’équipe de recherche LongCat-Flash a résolu le problème de launch-bound causé par les surcoûts de lancement de noyaux dans les systèmes d’inférence LLM. En particulier, après l’introduction du décodage spéculatif, l’ordonnancement indépendant des noyaux de validation et de passage avant du brouillon génère des surcoûts notables. Grâce à la stratégie de fusion TVD, ils ont fusionné le passage avant cible, la validation et le passage avant du brouillon dans un seul graphe CUDA. Pour améliorer encore l’utilisation du GPU, ils ont mis en œuvre un ordonnanceur superposé et introduit un ordonnanceur superposé multi-étapes, lançant plusieurs étapes de passage avant dans une seule itération d’ordonnancement, masquant efficacement les surcoûts d’ordonnancement et de synchronisation CPU.
L’optimisation des noyaux personnalisés cible les défis d’efficacité propres à l’auto-régression de l’inférence LLM. La phase de pré-remplissage est gourmande en calcul, tandis que la phase de décodage, en raison de la petite taille et de l’irrégularité des lots générés par le schéma de flux, est souvent limitée par la mémoire. Pour MoE GEMM, ils utilisent la technique SwapAB, considérant les poids comme la matrice de gauche et les activations comme la matrice de droite, maximisant l’utilisation des cœurs tensoriels grâce à la flexibilité de granularité de 8 éléments sur la dimension n. Les noyaux de communication exploitent l’accélération matérielle de diffusion et de réduction in-switch de NVLink Sharp pour minimiser les déplacements de données et l’occupation des SM, surpassant constamment NCCL et MSCCL++ sur des tailles de message de 4 Ko à 96 Mo avec seulement 4 blocs de threads.
En matière de quantification, LongCat-Flash adopte le même schéma de quantification fine par bloc que DeepSeek-V3. Pour un compromis optimal entre performance et précision, il applique une quantification hybride à plusieurs niveaux basée sur deux schémas : le premier identifie certaines couches linéaires (notamment Downproj) dont les activations d’entrée atteignent des amplitudes extrêmes de 10^6 ; le second calcule l’erreur de quantification FP8 par bloc pour chaque couche, révélant des erreurs significatives dans certaines couches d’experts. En croisant les deux schémas, une nette amélioration de la précision est obtenue.
Données pratiques : quelle vitesse ? Quel coût ?
Les performances réelles montrent que LongCat-Flash excelle dans divers contextes. Par rapport à DeepSeek-V3, à longueur de contexte similaire, LongCat-Flash offre un débit de génération supérieur et une vitesse de génération plus rapide.
Dans les applications d’Agent, en tenant compte des besoins différenciés entre le contenu d’inférence (visible pour l’utilisateur, devant correspondre à une vitesse de lecture humaine d’environ 20 tokens/s) et les commandes d’action (invisibles pour l’utilisateur mais impactant directement le temps de démarrage des outils, nécessitant la vitesse maximale), la vitesse de génération proche de 100 tokens/s de LongCat-Flash maintient la latence d’appel d’outil par tour à moins d’une seconde, améliorant considérablement l’interactivité des applications d’Agent. En supposant un coût de 2 dollars par heure pour un GPU H800, cela correspond à un prix de 0,7 dollar par million de tokens générés.
L’analyse théorique des performances montre que la latence de LongCat-Flash dépend principalement de trois composants : MLA, all-to-all dispatch/combine et MoE. Avec EP=128, batch par carte=96, taux d’acceptation MTP ≈ 80 %, la limite théorique de TPOT de LongCat-Flash est de 16 ms, contre 30 ms pour DeepSeek-V3 et 26,2 ms pour Qwen3-235B-A22B. En supposant un coût de 2 dollars par heure pour un GPU H800, le coût de sortie de LongCat-Flash est de 0,09 dollar par million de tokens, bien inférieur à celui de DeepSeek-V3 (0,17 dollar). Cependant, ces chiffres ne représentent que la limite théorique.
Nous avons également testé la page d’expérience gratuite de LongCat-Flash.
Nous avons d’abord demandé à ce grand modèle d’écrire un article sur l’automne, d’environ 1 000 mots.
Dès que nous avons formulé la demande et lancé l’enregistrement, LongCat-Flash avait déjà rédigé la réponse, si vite que nous n’avons même pas eu le temps d’arrêter l’enregistrement à temps.
En observant attentivement, on remarque que la vitesse de sortie du premier token de LongCat-Flash est particulièrement rapide. Avec d’autres modèles de dialogue, il arrive souvent de devoir attendre, ce qui met la patience de l’utilisateur à l’épreuve, comme lorsqu’on attend un message sur WeChat et que le téléphone affiche « en cours de réception ». LongCat-Flash change cette expérience, rendant la latence du premier token pratiquement imperceptible.
La génération des tokens suivants est également très rapide, bien au-delà de la vitesse de lecture humaine.
Ensuite, nous avons activé la « recherche en ligne » pour tester la rapidité de cette fonctionnalité de LongCat-Flash. Nous lui avons demandé de recommander de bons restaurants près de Wangjing.
Le test montre clairement que LongCat-Flash ne met pas longtemps à réfléchir avant de répondre, mais fournit presque instantanément une réponse. La recherche en ligne donne également une impression de « rapidité ». De plus, il cite ses sources lors de la sortie rapide, garantissant la fiabilité et la traçabilité des informations.
Les lecteurs ayant la possibilité de télécharger le modèle peuvent l’exécuter localement pour vérifier si la vitesse de LongCat-Flash est tout aussi impressionnante.
L’ère de la praticité des grands modèles
Ces dernières années, à chaque sortie d’un grand modèle, tout le monde s’intéressait à ses benchmarks, au nombre de classements battus, à son statut SOTA. Aujourd’hui, la situation a changé. À capacités similaires, la question est : ce modèle est-il cher à utiliser ? Est-il rapide ? Chez les entreprises et développeurs utilisant des modèles open source, cette tendance est encore plus marquée. Beaucoup choisissent l’open source pour réduire leur dépendance et leurs coûts vis-à-vis des API propriétaires, d’où une sensibilité accrue aux besoins en calcul, à la vitesse d’inférence et à l’efficacité de la compression/quantification.
Le modèle open source LongCat-Flash de Meituan incarne parfaitement cette tendance. Ils se concentrent sur la possibilité d’utiliser réellement les grands modèles à moindre coût et à grande vitesse, un point clé pour la démocratisation technologique.
Ce choix pragmatique est cohérent avec l’image que nous avons toujours eue de Meituan. Par le passé, la majorité de leurs investissements technologiques visaient à résoudre des problèmes concrets, comme l’article EDPLVO, lauréat du prix de la meilleure navigation à l’ICRA 2022, qui répondait aux imprévus rencontrés par les drones de livraison (par exemple, la perte de signal due à la densité des immeubles) ; ou encore leur participation récente à la définition de la norme ISO mondiale d’évitement d’obstacles pour drones, fruit de leur expérience dans des cas tels que l’évitement de fils de cerf-volant ou de cordes de nettoyage de vitres. Le modèle LongCat-Flash open source est en fait le moteur de leur outil de programmation IA « NoCode », qui sert à la fois en interne et est ouvert gratuitement à l’extérieur, dans l’espoir que tout le monde adopte le vibe coding pour réduire les coûts et améliorer l’efficacité.
Ce passage de la compétition de performance à une approche pragmatique reflète en réalité la logique naturelle de l’évolution du secteur de l’IA. À mesure que les capacités des modèles convergent, l’efficacité d’ingénierie et le coût de déploiement deviennent les facteurs de différenciation clés. L’open source de LongCat-Flash n’est qu’un exemple de cette tendance, mais il offre à la communauté une voie technique de référence : comment, tout en maintenant la qualité du modèle, abaisser la barrière d’utilisation grâce à l’innovation architecturale et à l’optimisation système. Pour les développeurs et entreprises au budget limité mais désireux de bénéficier des capacités avancées de l’IA, c’est indéniablement précieux.
Avertissement : le contenu de cet article reflète uniquement le point de vue de l'auteur et ne représente en aucun cas la plateforme. Cet article n'est pas destiné à servir de référence pour prendre des décisions d'investissement.
Vous pourriez également aimer
Il ne reste plus qu’un mois ! Le compte à rebours pour la « fermeture » du gouvernement américain recommence à tourner
Ce n’est pas seulement une question d’argent ! L’affaire Epstein et les agents fédéraux sont autant de "mines" qui pourraient déclencher une crise de fermeture du gouvernement américain...
QuBitDEX est le sponsor principal du premier sommet en ligne sur la blockchain à Taïwan (TBOS), créant le plus grand événement industriel en ligne d'Asie.
Le premier sommet en ligne sur la blockchain de Taïwan, TBOS, se tiendra en septembre 2025. En collaboration avec TBW, MYBW et d'autres partenaires, il se concentrera sur les applications décentralisées et la transition du Web2 vers le Web3, dans le but de créer le plus grand événement Web3 en ligne d'Asie. Résumé généré par Mars AI. Ce résumé a été produit par le modèle Mars AI, dont l'exactitude et l'exhaustivité font encore l'objet d'améliorations continues.

