
OpenAI et Anthropic testent mutuellement leurs modèles sur des questions d'hallucination et de sécurité

Jinse Finance rapporte que OpenAI et Anthropic ont récemment évalué mutuellement les modèles de l’autre afin d’identifier des problèmes potentiellement omis lors de leurs propres tests. Les deux entreprises ont déclaré mercredi sur leurs blogs respectifs qu’au cours de cet été, elles avaient effectué des tests de sécurité sur les modèles d’IA accessibles publiquement de l’autre, et examiné si ces modèles présentaient des tendances à l’hallucination, ainsi que des problèmes dits de “désalignement”, c’est-à-dire lorsque le modèle ne fonctionne pas comme prévu par les développeurs. Ces évaluations ont été réalisées avant le lancement par OpenAI de GPT-5 et la sortie par Anthropic d’Opus 4.1 début août. Anthropic a été fondée par d’anciens employés de OpenAI.
Avertissement : le contenu de cet article reflète uniquement le point de vue de l'auteur et ne représente en aucun cas la plateforme. Cet article n'est pas destiné à servir de référence pour prendre des décisions d'investissement.
Vous pourriez également aimer
Données : Classement des flux entrants/sortants de fonds au comptant sur 24 heures
En vogue
PlusLa probabilité que la Fed abaisse à nouveau ses taux de 25 points de base en janvier est de 24,4 %, et la probabilité d'une baisse cumulative de 50 points de base d'ici mars est de 8,1 %.
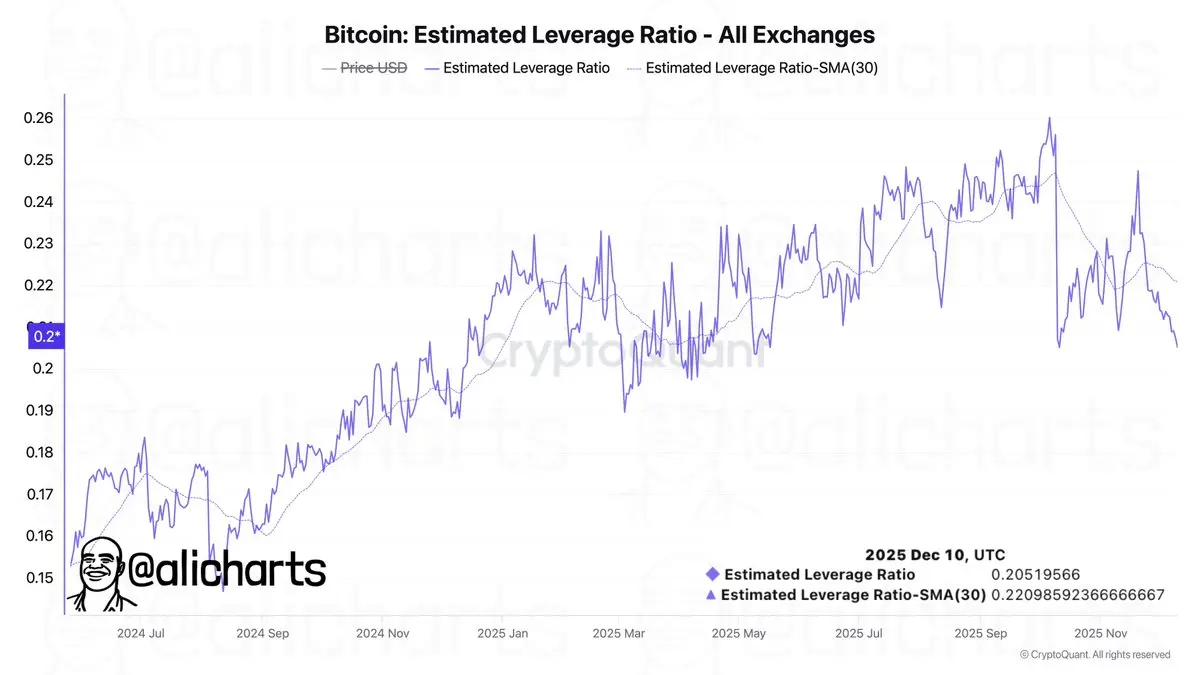
Analyse : En raison de l’aversion au risque des investisseurs, le niveau de levier sur les plateformes d’échange est tombé à son plus bas niveau depuis 5 mois.